VDCores: A Runtime for Modern Async GPUs
Author: Zhiyuan Guo, Zijian He, Adrian Sampson and Yiying Zhang
🎉 VDCores is now open source! Check out the repository at github.com/vdcores/vdcores and give it a spin.
Modern GPUs increasingly expose asynchronous execution engines, but today’s kernels still linearize memory movement, computation, and control into a single SIMT program, making overlap and composability brittle and architecture-specific. Virtual Decoupled Cores (VDCores) decouples memory, compute, and control, reconnecting them only through explicit dependencies. VDCores reduces kernel code by ~67% , enables kernel reuse across variants, and delivers ~12% performance gains compared to existing solutions.
In this post, we will cover:
- Why GPU programming needs a new model: GPU resources are increasingly heterogeneous and asynchronous; programming must adapt, but doing so under the current model adds significant complexity.
- The principle and practice of decoupling: We introduce decoupled cores, a new programming model that untangles GPU kernels into state isolated, asynchronous execution units, and show how this enables composability (without performance overhead).
- What flexibility enables: Beyond faster and simpler programming, what new system-level resource patterns and optimizations that VDCores make possible.
GPUs Are Becoming Asynchronous, Kernel Programming Is Becoming Messy
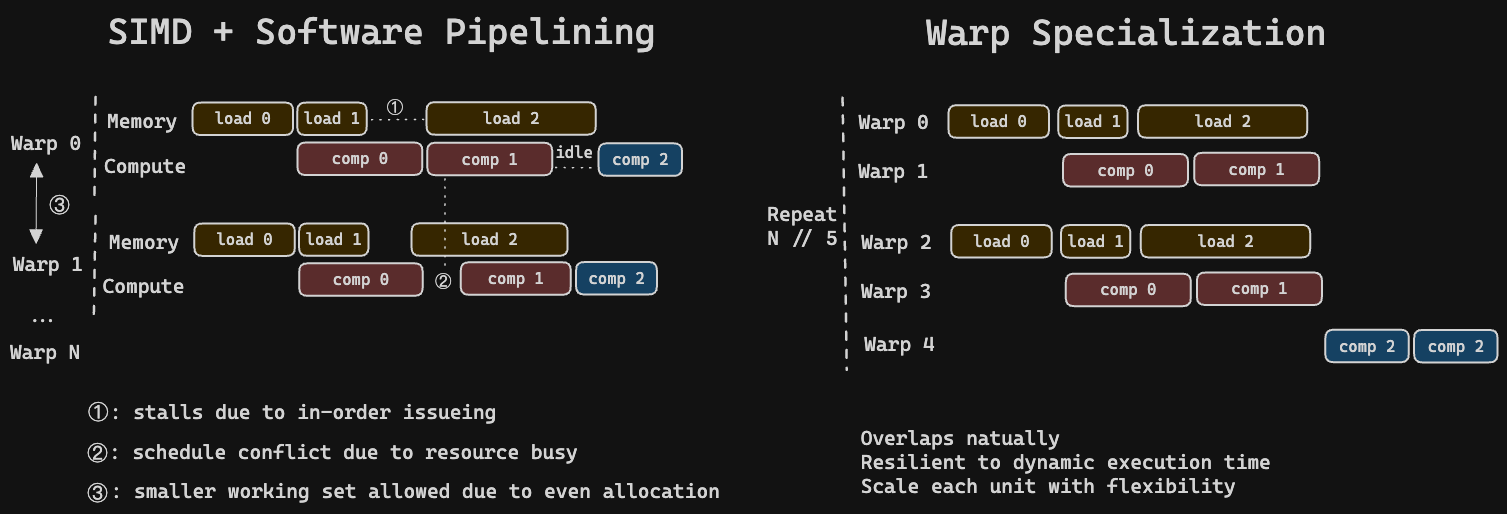
Modern GPUs are no longer “just” wide SIMD machines. They are increasingly asynchronous systems with heterogeneous resources that each operate on their own timelines: tensor cores run independently, memory pipelines have their own queues, and async copy engines allow data movement to proceed concurrently with computation. Programming should adapt to this asynchronous style — and the performance rewards for doing so are real.
But the prevailing GPU programming model couples memory movement, computation, and control into a single linearized thread program. A typical hand-tuned kernel ends up as a monolithic SIMT program that manually interleaves: (1) memory management, (2) async memory movement, (3) tensor core scheduling, and (4) CUDA core SIMT operations. Every kernel is forced to simultaneously express what data must move, what compute must run, and how to schedule and synchronize the two.
This coupling amplifies complexity. Performance features like prefetching, pipelining, and computation-communication overlap become manual, fragile to workload and environment change, and architecture-specific responsibilities. The result: kernels that are hard to read, hard to maintain across GPU generations, and hard to compose into larger pipelines.
How to Make Programmer’s Life Easier With a Decoupled Mind
We adopt the key principle of how software systems controls the complexity of asynchonous: Resource/state isolation and asynchronous through message passing, and rebuild GPU SMs to decoupled cores.
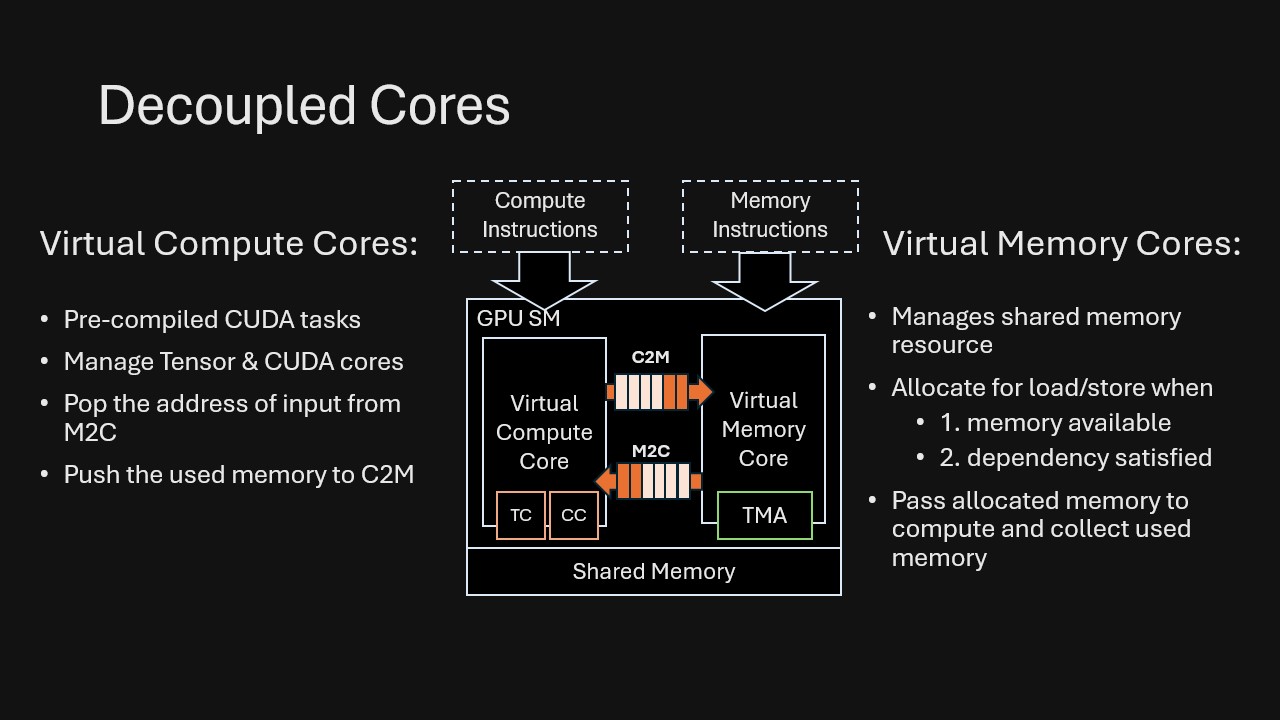
In the VDCores model, virtual cores are the unit of execution and composition. Instead of a single monolithic kernel, execution is decomposed into independent instruction streams executed by loosely coupled cores.
Each decoupled core specializes in a single resource type (e.g., compute or memory) and executes instructions solely based on its local state. For example, within a decoupled memory core, a load instruction can be issued as soon as its dependencies are satisfied and sufficient local shared memory is available, regardless of the state of the compute core. When dependency information must be exchanged between decoupled cores, they communicate via asynchronous message queues. Messages do not need to be processed immediately; the receiver can handle them at any time, enabling flexible and loosely synchronized coordination between cores.
This design fully decoupling memory, compute, and control, and reconnecting them only through explicit dependencies . Once dependencies are first-class, the runtime (and compiler) can safely exploit concurrency: prefetching, latency hiding, double-buffering, and overlap are no longer hand-tuned tricks but emergent behaviors that come “for free” from the decoupled execution model.
This structure makes dependencies explicit and enables safe parallelism among instructions that are not truly dependent. For example, memory core in VDCores naturally covers the common dependency patterns we see in real kernels without requiring programmers to manually linearize them: (Compute cores works in a similar dependency-driven style)
- Read-read without dependency are allowed to be reordered in memory core.
- Read-after-write without dependency are allowed to be overlapped: read could execute first and write to be committed later when dependency satisfied.
- Read/write with control flow: decouple control decisions (issue) from memory completion so that control does not unnecessarily block data movement.
VDCores also draws on ideas from microarchitectural design. Its core approach is to rebalance responsibilities between the runtime and the programmer/compiler:
- Programmers/Compiler focus on specifying what must happen and being precise about dependencies (what consumes what), rather than hand-inlining a separate “prefetch” phase and then a “compute” phase.
- The runtime owns control flow and runtime management: scheduling memory/compute operations, managing in-flight instructions, and allocating local memory spaces as they become available.
For readers interested in how we efficiently implement this abstraction on real GPU hardware, see the Deep Dive at the end of this post.
Here’s a quick example of how VDCores simplify the programming and at the same time covers the common performance pitfall for you. We build VDCores by composing only 5 basic compute instructions and 23 memory/control instructions, and use them to compose all operators used in QWen-8B inference. Compared to a state-of-the-art megakernel implementation, Mirage Persistent Kernel, VDCores use 67% fewer lines of code and achieves over 12% performance gain.
VDCores do not get this edge by hand-tunning better kernels, but instead through decouopled runtime and flexbile programming interface. We illustrate this with two exmples in this process.
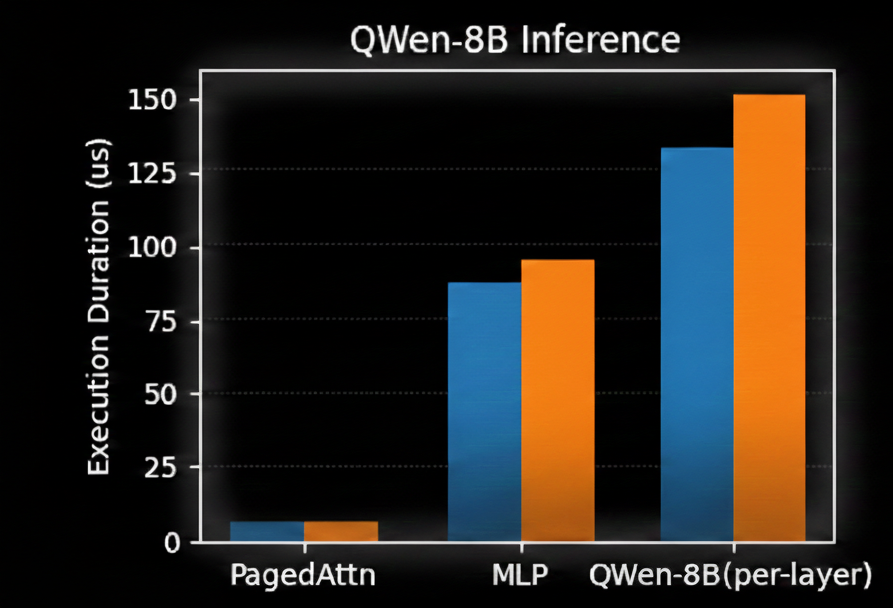
Example 1: Free “Prefetch” Non-Dependent Memory Buffers
Consider an attention kernel followed by a linear projection with residual addition. In VDCores, we connect them by dependencies rather than manually fusing/staging: (Also note that in VDCores we do not have the notion of kernel boundary; we mark the original kernel boundary in the example for ease of understanding.)
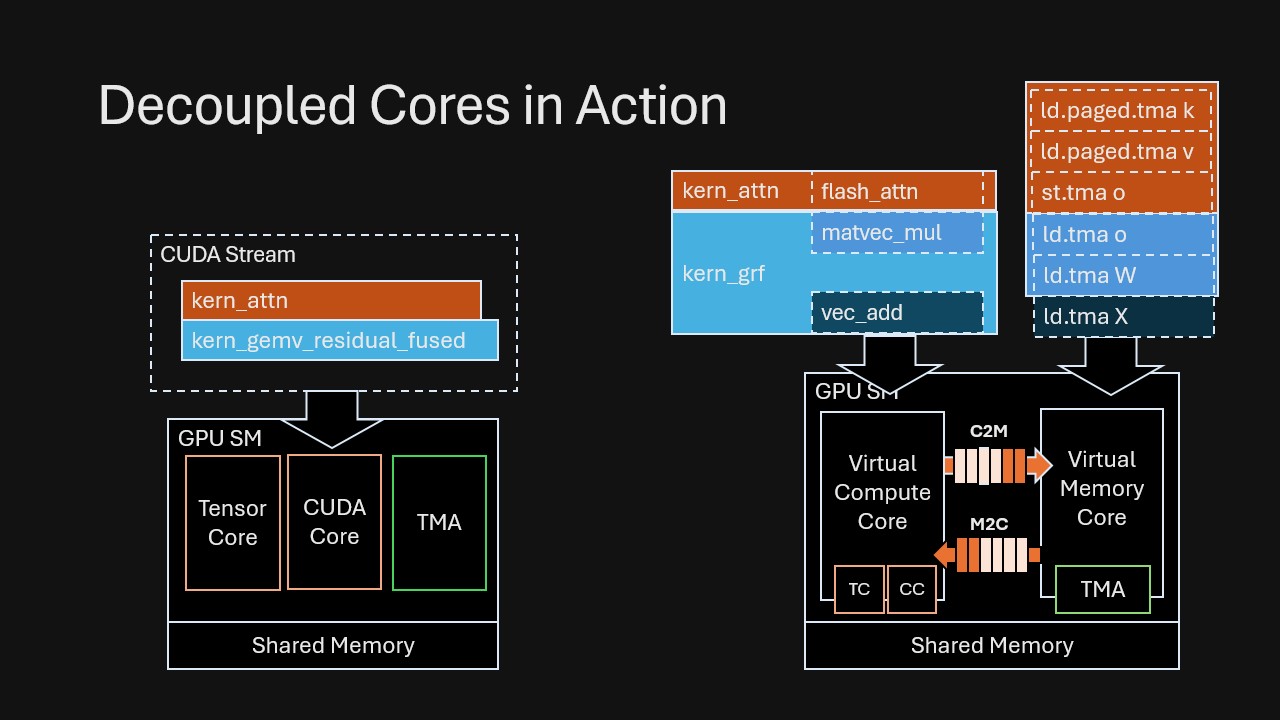
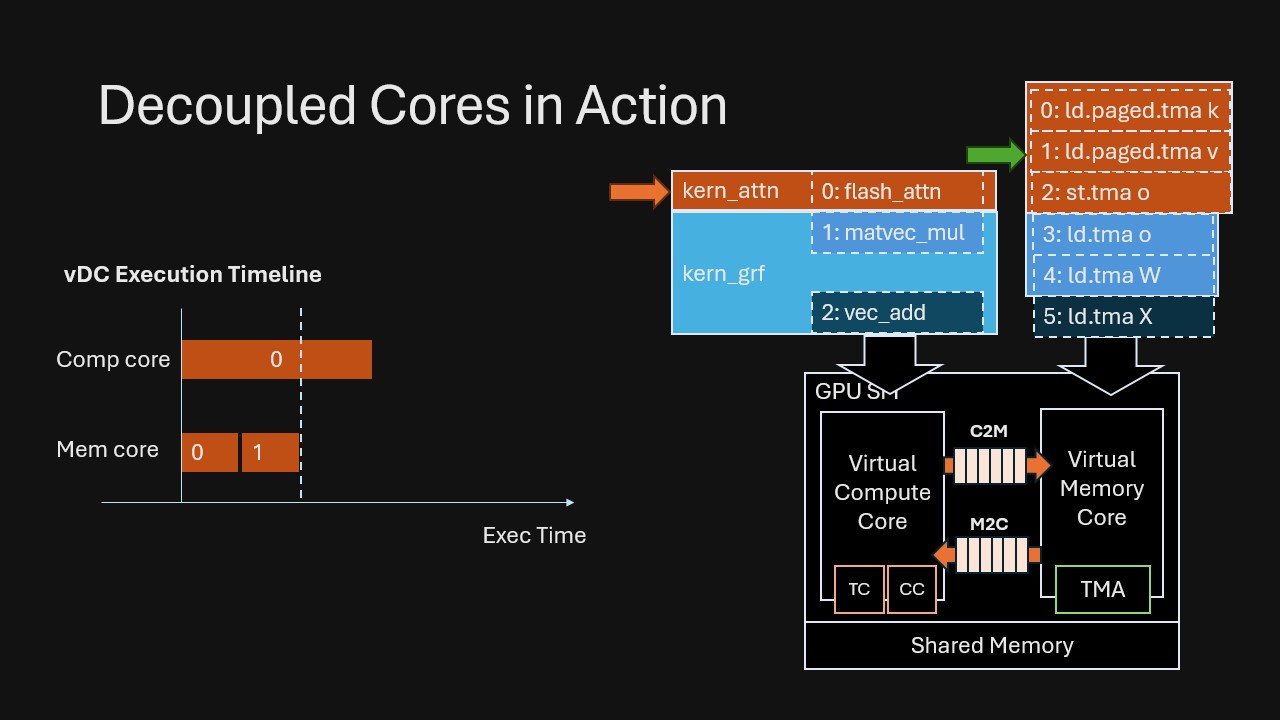
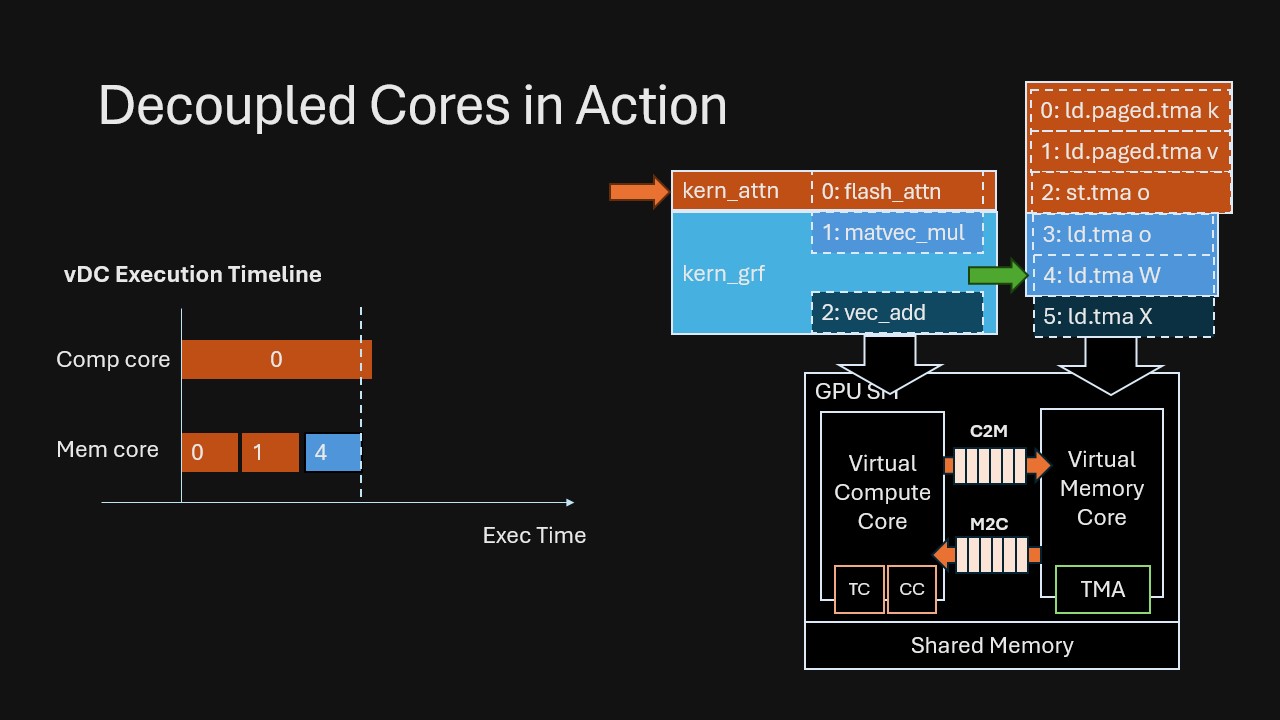
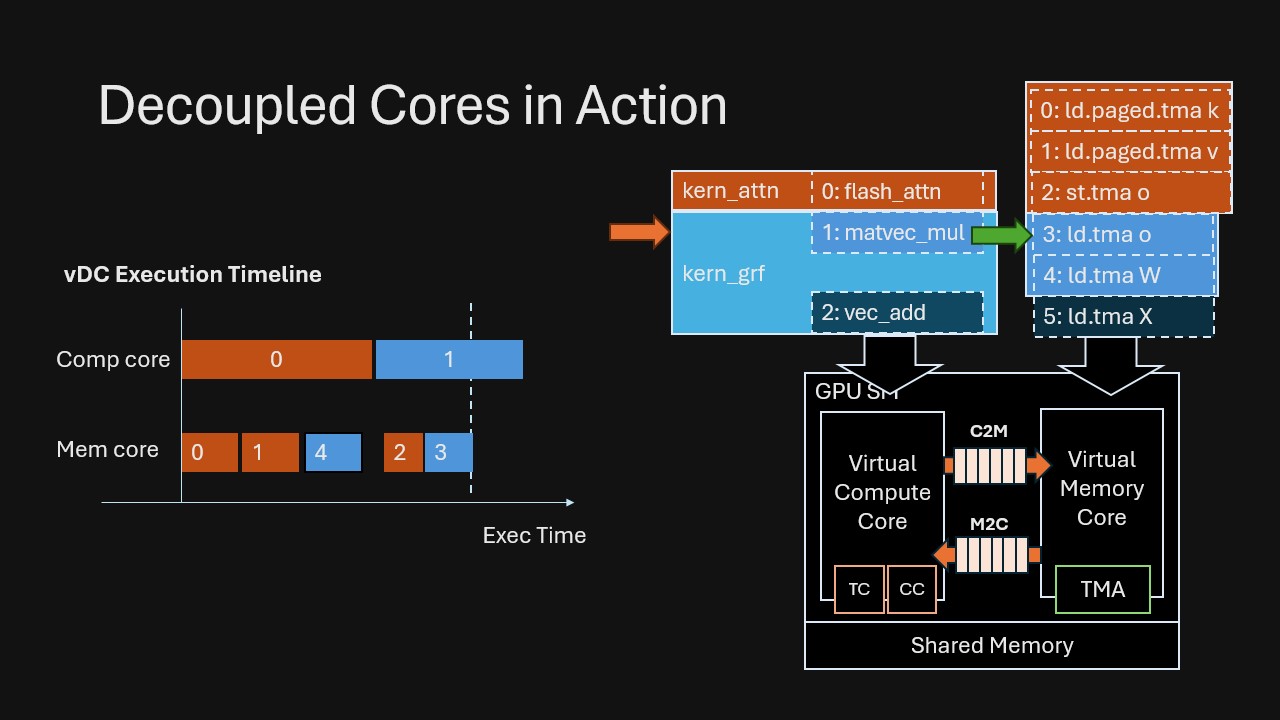
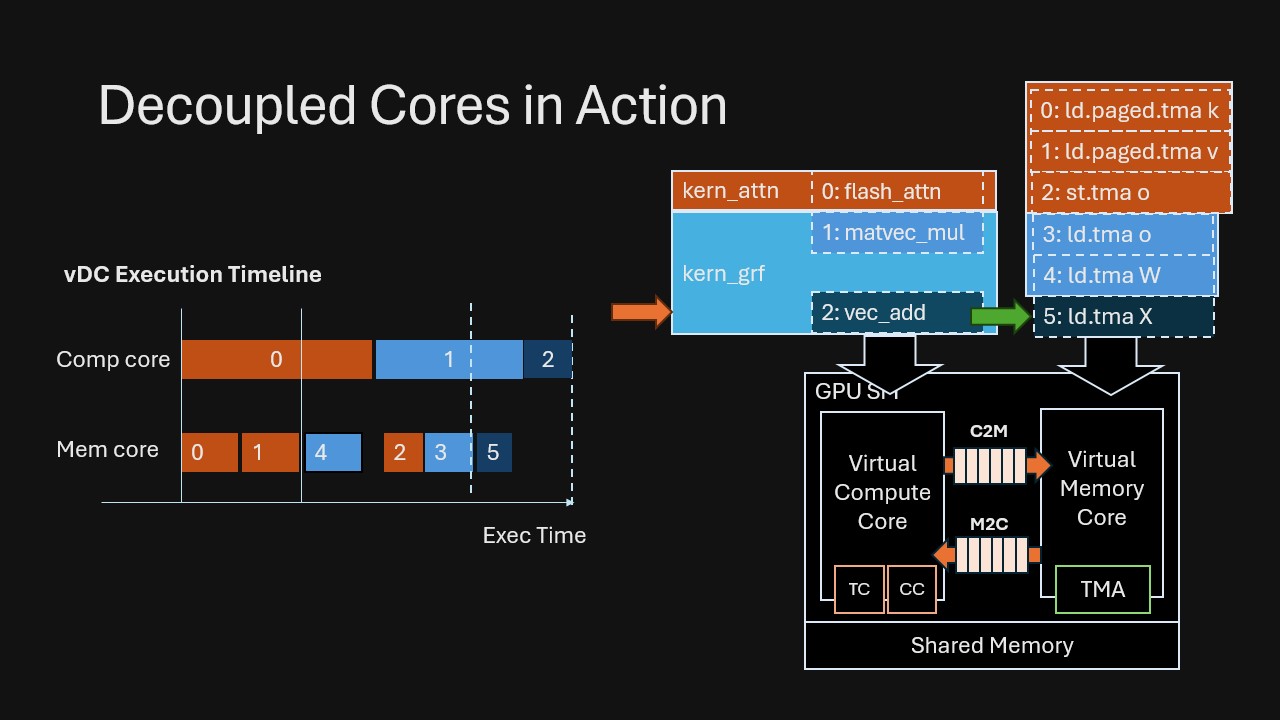
This is the key shift: Overlap emerges automatically from runtime dependency resolving, without humans splitting code into explicit “prefetch” stages or manually fusing kernels to force concurrency.
Example 2: Flexible and Zero-Overhead Core Composition
Another secret sause of VDCores is the composbility of it’s components. Same set of computation instructions could be composed with different memory instructions, different memory dependencies, thus allowing programmer to quick experimenting with different plans without manual kernel rewrite and fusion.
Consider an MLP block: GEMV (Up + Gate) followed by SiLU activation and GEMV (Down). Input is shape [1, 4096], Up and Gate outputs are [1, 12288], and Down output is [1, 4096]. We can tile Gate and Up along the N dimension and Down along the K dimension.

Schedule 1 executes the operations in order and fuses SiLU with Up—straightforward and amenable to kernel fusion for optimization.
Schedule 2 exploits output-tile-level dependencies and lets the runtime automatically achieve more overlap: as soon as a Gate+Up tile pair completes, SiLU runs on 4 spare SMs without stalling the Down projection, which can begin consuming earlier tiles immediately.
Hard to tell which one is faster Huh? Manually morphing between these two schedules requires significant changes to the kernel implementation. With decoupled cores abstraction, switching between them requires instruction flow level change, all tasks remain composable, without sacrificing performance. We try both with in 10 minutes with VDCores, and get a quick 7% performance gain in this operator.
Deep Dive: Turning GPU SMs into Virtual Decoupled Cores
We turn every SM on H200 into a pair of Memory/Compute decoupeld cores, connected by message queues, all run at the speed of GPU!
We built Virtual Decoupled Cores on top of the GPU’s SM hardware. Making these virtual components keep up with raw GPU speed poses a major performance challenge. To reach PFLOPs of compute and multi-terabytes-per-second memory bandwidth, every SM cycle counts, and there is only limited headroom for virtual-core overheads.
Our main idea is to build virtual software memory cores and compute cores on top of warps , and let them communicate through explicit queues and ports. VDCores assembles the warps within a single SM into two kinds of “cores” (memory cores and compute cores), implementing a small, software-defined superscalar processor. On the memory side, we expose (i) an allocation & branch / control unit, and (ii) configurable load and store units, all running asynchronously.
Recall that VDCores aim to achieve pipelining without programmers explictly defining them. Under this principle, some designs emerge to further optimize the performance while keeping the flexibility:
- Instruction issue is ordered but completion can be out-of-order. Control flow keeps program order when needed, while the load dispatch unit (LDU) can complete loads out of order (with compiler hints) to unlock overlap.
- Programmable dependencies with software-controlled virtual ports. Control logic routes instructions to load/store “engines” without baking scheduling policy into every kernel.
Decoupled Cores: In Live Action and in the Wild
We are continuing to expand VDCores to a wider range of cores and hardware platforms. Stay tuned!
VDCores’s decoupled model goes beyond cleaner way to write one kernel, it is a substrate for systematic overlap and composition . Once memory, compute, and control communicate only through explicit dependencies, we can schedule and explore pipelines at a higher level and let the runtime safely exploit concurrency and performance. Here’s exciting directions we are exploring and may reveal the full potential of VDCores system:
- Communication Virtual Cores: VDCores are all about isolating and decomposing work into separate, decoupled components, and communication/networking should be one of them. Whether it is inter-rack communication over InfiniBand or communication between GPUs, it composes naturally with existing memory and compute decoupled cores.
- Adapting to Tiered Memory and new Arch: By decoupling issue/completion and separating memory/compute concerns, the same kernel structure can adapt to evolving GPU mechanisms (e.g., new async memory types on Blackwell), and wider range of memory locations and operations (e.g., ) without changing the VDCores application.
- Composition at Runtime: VDCores is designed to be a runtime substrate that makes it easier to compose kernels into larger pipelines, coordinate resource allocation, and reason about end-to-end overlap beyond traditional kernel boundaries. Given the power to compose any memory/compute operations dynamically at runtime, fine-grained, runtime-aware policies could be further explored.
We’ll cover these topics in future posts in this series. In the meantime, head over to github.com/vdcores/vdcores to explore the code, try it out, and contribute. Stay tuned!