TClone: Decoupling Fast Branch Creation from Durable Checkpointing for Computer-Use Agents
Author: Yutong Huang, Vikranth Srivatsa, Alex Asch, Hansin Tushar Patwa, and Yiying Zhang
TLDR: Computer-use agents increasingly want to branch: explore several actions in parallel, keep the best trajectory, and roll back the rest. But a branch of a desktop is an entire running workspace (processes, memory, files, GUI), and cloning it with today’s tools means a synchronous checkpoint-and-restore on the critical path of every speculative step. We built TClone, a workspace-versioning substrate built on a modified Linux kernel and an extended CRIU. Its one architectural principle is that online branch creation is separated from durable checkpointing: a branch becomes runnable through copy-on-write sharing without copying a single page on the critical path, while serialization to disk proceeds asynchronously and off that path. TClone clones a live workspace up to 4.9x faster than KVM snapshots and 3.4x faster than stock CRIU. Checkout our full paper on arxiv.
Computer-Use Agents Want to Branch
Computer-use agents (CUAs) drive a real desktop the way a person would. The strongest agent loops do not commit to one line of action: they run best-of-N, beam search, and rollback-heavy exploration, forking the current state, trying several next actions in parallel, keeping the winner, and discarding the rest. They also need a personal workspace the user keeps using, with speculative agent branches forked off it and either committed back or thrown away.
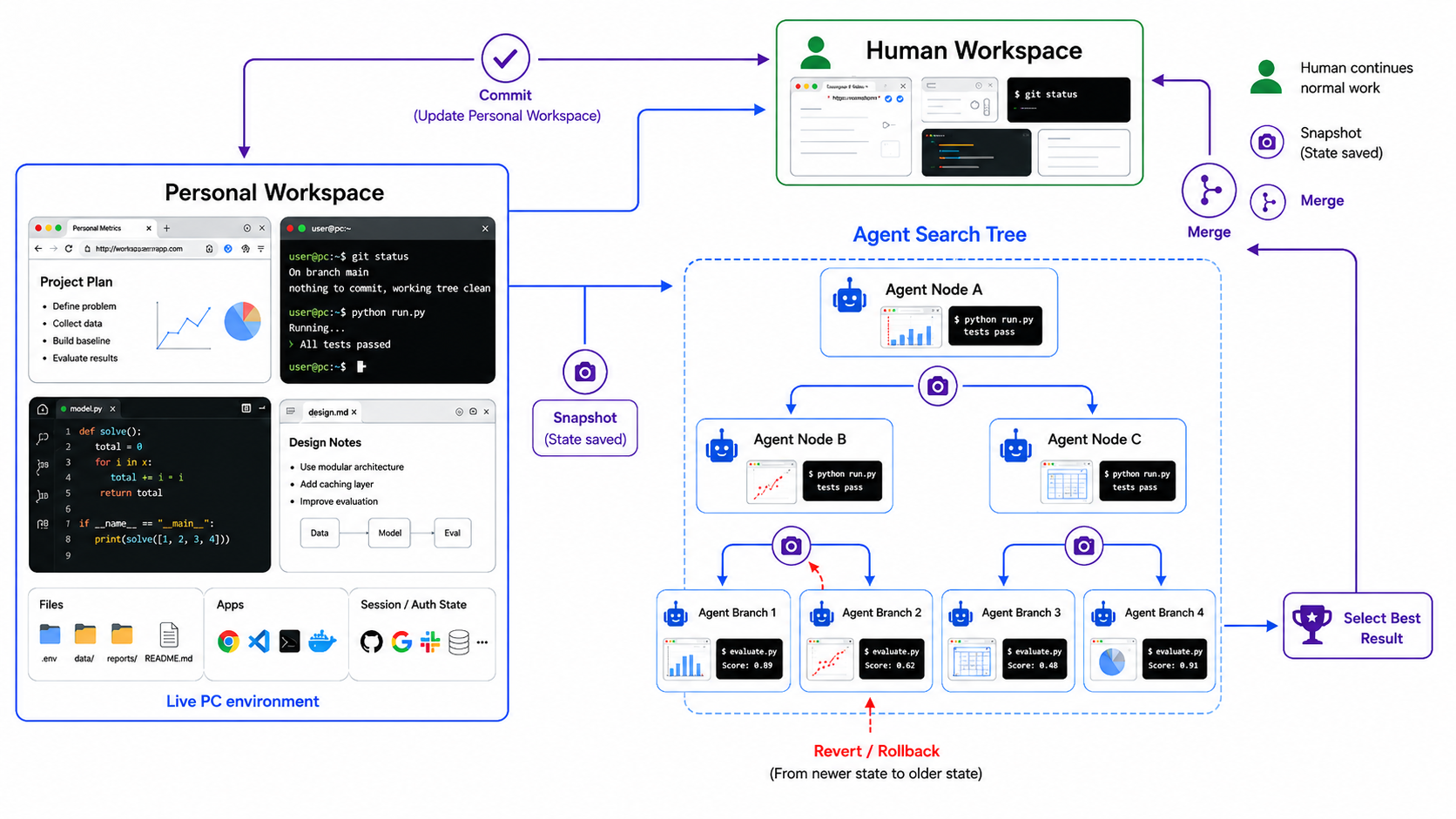
A versioned personal workspace: the live PC environment is branched into an agent search tree, branches are snapshotted and rolled back, and the selected result is committed back to the human's workspace.
The catch is that each fork is not a lightweight object. It is an entire live workspace: a process tree of a hundred-plus processes, gigabytes of memory, an open filesystem, and a running GUI stack. The usual ways to clone a running container, checkpoint/restore (CRIU) or a VM snapshot, serialize that whole workspace to storage and rebuild it, and that cost lands directly on the agent’s critical path at every branch point.
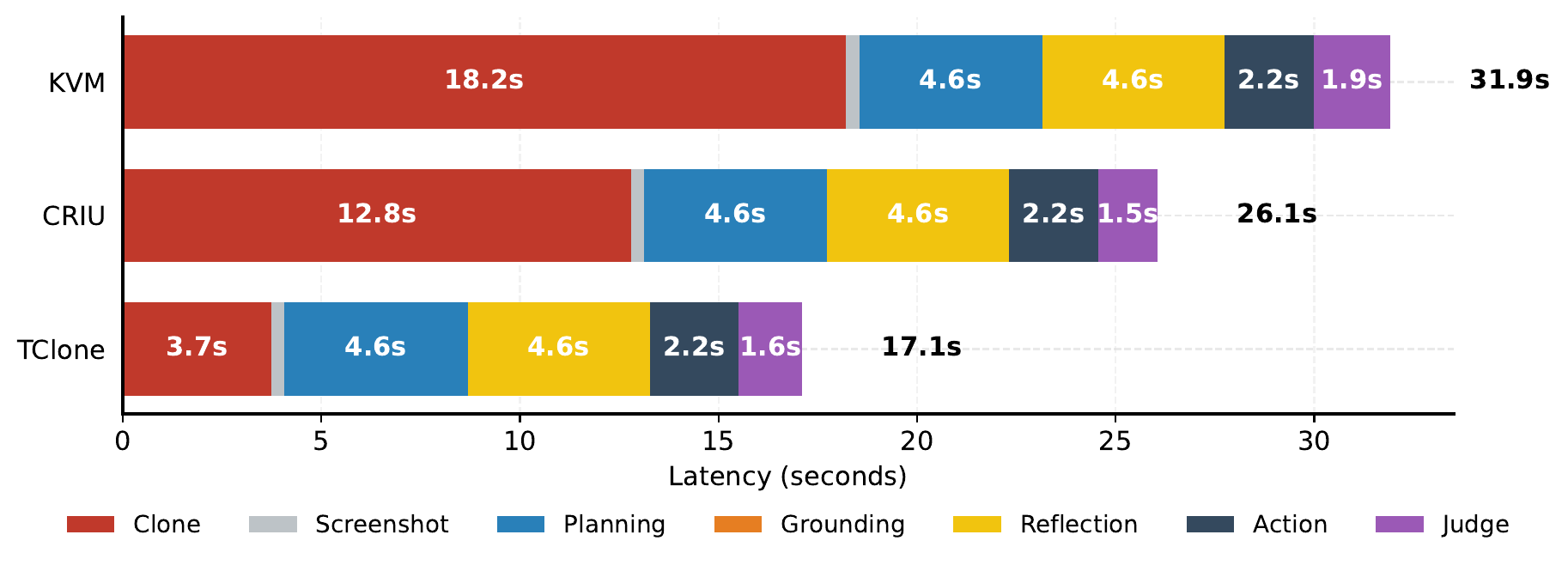
Per-branch cost for one OSWorld step. The clone segment (red) is 18.2s under KVM and 12.8s under CRIU, but only 3.7s under TClone; everything else is model-bound and identical.
Everything except that clone segment is model-bound and identical across systems. Stock CRIU spends 12.8s and a KVM snapshot 18.2s cloning a single branch; TClone spends 3.7s. Because the overhead recurs on every fork and rollback, it compounds: the more an agent branches, the more it pays.
The Big Idea: Decouple Fast Branching From Durable Checkpointing
Why is checkpoint/restore so slow? It conflates two things that do not need to happen together. To use a branch, the runtime needs a runnable copy of the workspace right now. To support rollback later, it needs a durable image on disk. Stock CRIU does both synchronously: dump the whole workspace, then restore it, with the branch blocked on both.
TClone’s entire design follows from one principle: online branch creation is separated from durable checkpointing. A branch is made runnable purely by copy-on-write (CoW) sharing, without copying a single page on the critical path; writing the durable image happens asynchronously, off that path, so nothing waits for the disk.
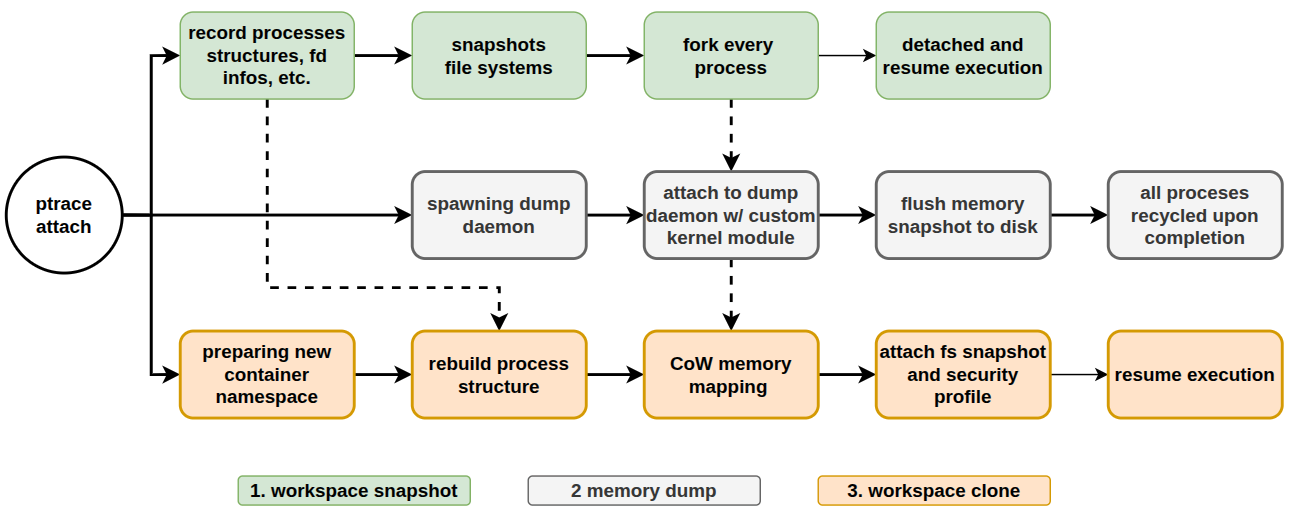
The fork pipeline. The source is frozen just long enough to capture metadata and set up CoW sharing, then resumes; a background daemon writes the durable image while the new branch is rebuilt in fresh namespaces.
Concretely, the source is frozen only long enough to record process metadata (the tree topology, namespaces, open files, registers) and set up CoW memory sharing. No page contents move while it is stopped, so the freeze time is independent of how big the workspace is. The source then resumes immediately while serialization and branch reconstruction finish in the background.
Rebuilding the Tree and Sharing Its Memory
A workspace is a tree of processes, and the topology is itself part of the state: which process is whose parent, who
shares a thread group, who lives in which namespace. You cannot rebuild it with plain fork(). If you individually fork
processes A, B, and C, the copies all become children of the originals instead of one another, so the tree comes
out wrong. TClone instead replays the recorded topology inside a fresh container, recreating each task with its original
namespace-local identity, so the application-visible process tree is preserved exactly while host-level process IDs
differ across branches and never collide.
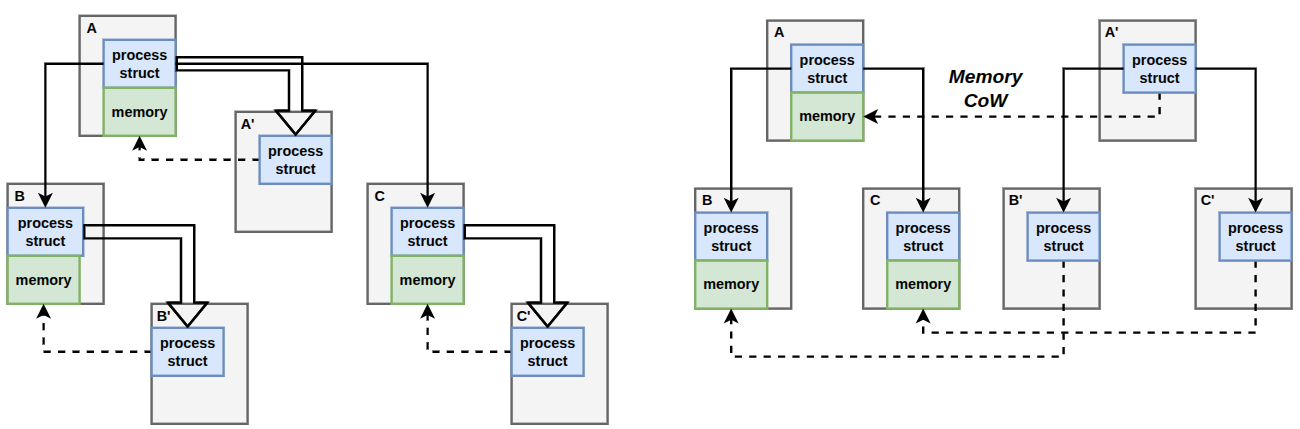
Naive per-process forking (left) makes each copy a child of its source, producing the wrong tree. TClone reconstructs the original topology (right) inside an isolated container and shares memory copy-on-write across the container boundary.
Memory is where the real savings are. A workspace is heavy, but a speculative branch usually touches only a little of it
before it is kept or thrown away, so TClone shares memory between branches and makes a private copy of a page only when
a branch writes to it. This is exactly what fork() already does for a parent and child. The catch, visible on the
right of the figure, is that a branch is not a child: it lives in a separately isolated container, so a plain fork()
cannot link them. TClone reuses the kernel’s own CoW machinery but extends it across the container boundary, so a branch
starts out sharing all of the source’s memory for free and diverges only page by page, and many branches at once cost no
more per branch than one. State that cannot be shared safely, such as the fast-changing GUI framebuffer, is kept
branch-local, which is also what stops a broken or malicious branch from reaching back into the user’s workspace.
Sharing Files Without Copying Them
Files get the same copy-on-write treatment, with one subtlety most people miss. Even on a filesystem like btrfs or ZFS that shares data blocks on disk between a snapshot and its origin, the page cache (the in-memory copy of file data) is tracked per file, not per block, so once a snapshot gets its own identity the kernel caches the very same bytes twice in RAM. Block-level CoW deduplicates on disk but not in memory. TClone closes that gap by making the page cache copy-on-write too: branches share sealed, read-only cached pages, and the first write to one copies it out privately into that branch alone. The result is a private, writable filesystem per branch that still shares all the read-mostly state (binaries, libraries, unchanged documents) for free.
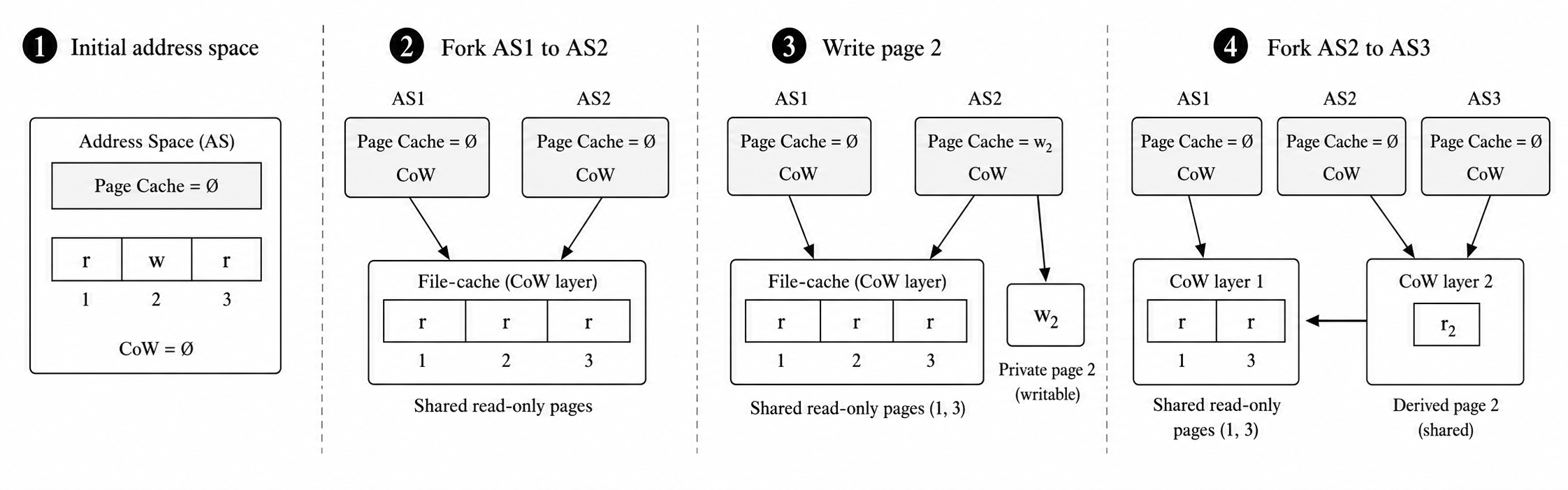
Lazy page-cache CoW. Forking a branch records a sealed read-only layer shared by sibling branches; a write copies out a private page and leaves the layer intact; a further fork derives a new layer so siblings share post-write state while ancestors keep the earlier version.
Keeping Branches Contained
A forked agent branch should not inherit the full authority of the user’s workspace. Most agent tasks need only a narrow slice of the environment: a browser or editor task rarely needs SSH keys, cloud credentials, or unrelated project files. TClone attaches a security profile to each branch at fork time, derived offline by recording what an application touches while a human operates it and enforced with standard sandboxing (seccomp and an LSM such as SELinux). The agent never participates in shaping its own profile, so it cannot widen it.
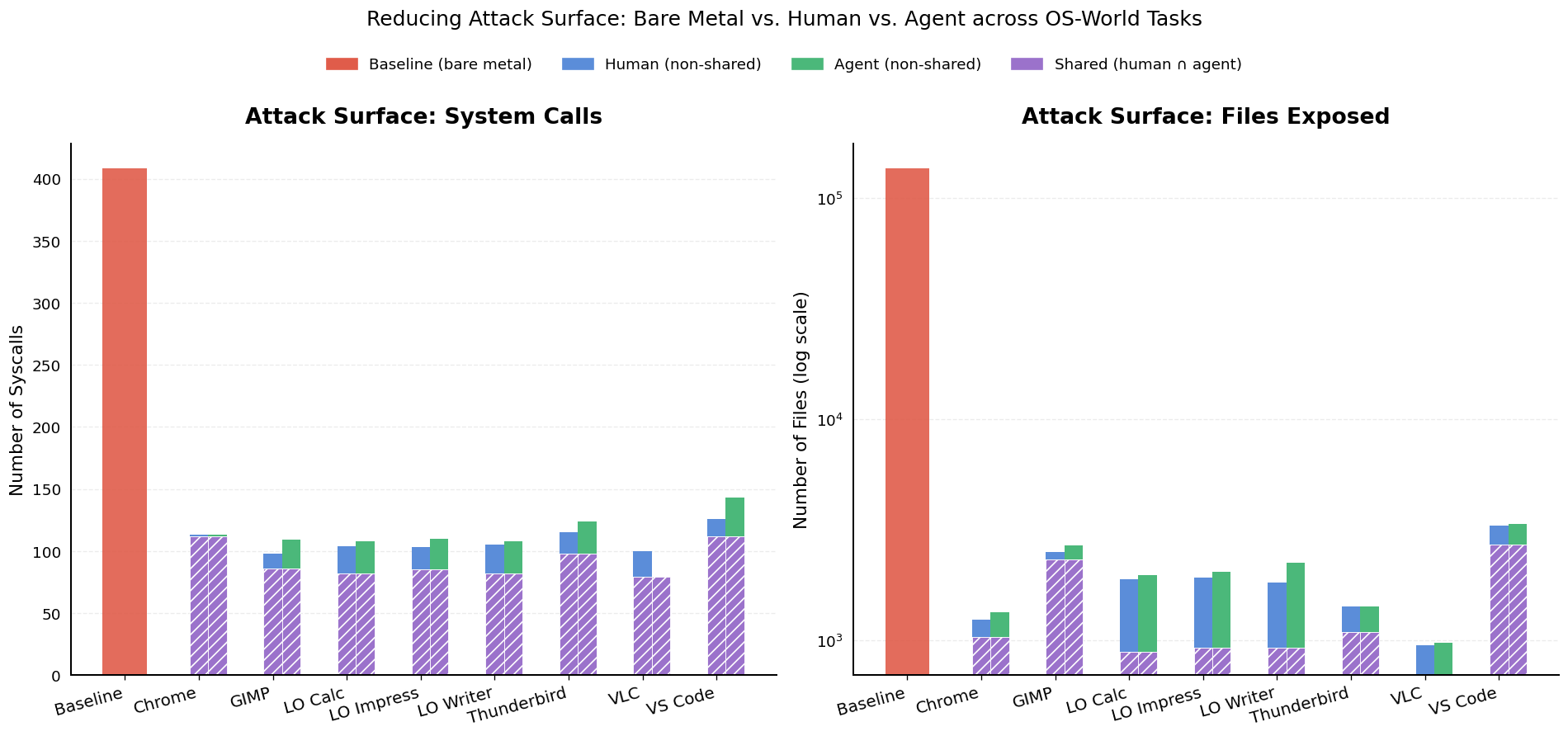
Reachable attack surface across OSWorld applications. Per-application profiles cut the syscall and file surface far below bare metal; most of what remains is shared between the human and the agent, and the agent-only delta is small.
The effect is that protection moves out of prompts and agent behavior and into the substrate: a branch is forked with only the resources its task requires, so most secrets are simply unreachable in the first place.
How Well Does It Work?
We evaluate TClone on two agent setups, AgentLoop on GTA and Agent S3 on OSWorld, with the workload, trajectories, and model held fixed so only the versioning substrate varies. We compare against stock CRIU and a KVM snapshot baseline.
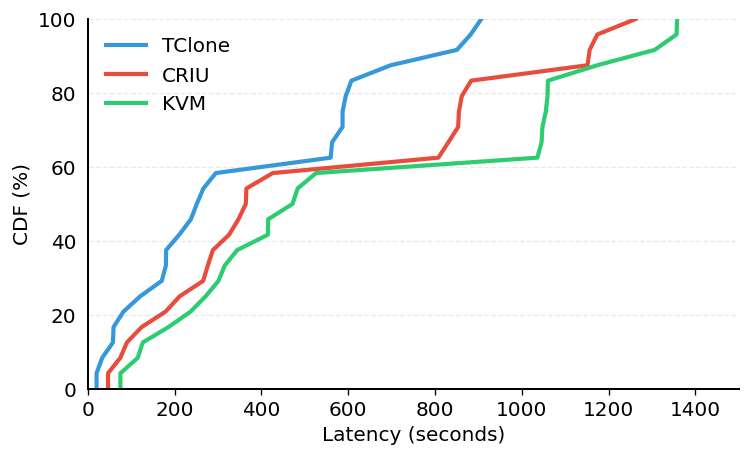
End-to-end task-latency CDF on Agent-S3/OSWorld. TClone shifts the whole distribution left of CRIU and KVM.
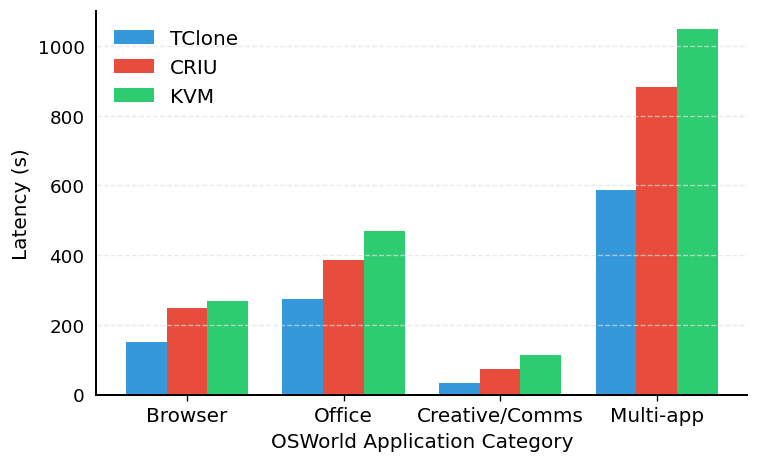
The same OSWorld latency split by task category. The gap is widest on multi-application workspaces.
End-to-end, TClone shifts the entire latency distribution left of CRIU and KVM, not just the median: up to 2.3x faster than CRIU and 3.7x faster than KVM on the heavier OSWorld desktop tasks. The gains are largest on short tasks and multi-application workspaces, exactly where unchanged memory and read-mostly files are shared instead of re-materialized per branch.
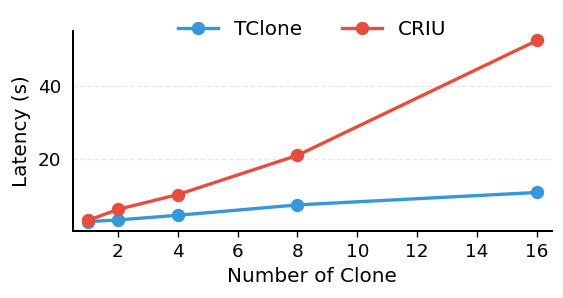
Clone latency as concurrent clones increase. CRIU exceeds 50s at 16 clones; TClone stays near 10s.
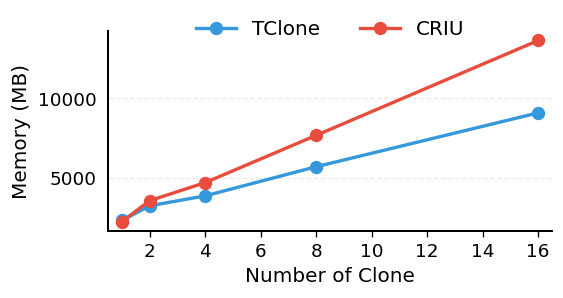
Memory footprint vs. clone count. TClone stays around 9 GB where CRIU reaches 14 GB at 16 clones.
The setting that matters most is keeping many branches alive at once for beam search and rollback. At 16 concurrent clones CRIU needs over 50s and 14 GB while TClone stays near 10s and 9 GB, and both gaps keep widening. The reason is simply that TClone shares unchanged state instead of recreating the whole workspace each time, so its cost grows only with what a branch actually changes, not with how big the workspace is. That is what lets an agent run a much wider search before time or memory runs out.
Our Vision
Agent loops are becoming search procedures over a real machine, and search means branching. We think the workspace substrate, not the agent framework, is where that branching should be made cheap. TClone’s takeaway is that creating a runnable branch and writing a durable checkpoint are two different jobs that today’s tools force into one blocking step: separate them, and a branch becomes just copy-on-write sharing plus a background flush, and the cost of speculation drops from a full-workspace checkpoint to just the working set you actually diverge on.