Author: Vikranth Srivatsa and Yiying Zhang
LLM prompts are growing more complex and longer with agents, tool use, large documents, video clips, and detailed few-shot examples. These prompts often have content that is shared across many requests. The computed intermediate state (KV cache) from one prompt can be reused by another for their shared parts to improve request handling performance and save GPU computation resources. However, current distributed LLM serving systems treat each request as independent and miss the opportunity to reuse the computed intermediate state.
We introduce Preble, the first distributed LLM serving system that targets long and shared prompts. Preble achieves a 1.5-14.5x average and 2-10x p99 latency reduction over SOTA serving systems. The core of Preble is a new E2 Scheduling that optimizes load distribution and KV cache reutilization. Preble is compatible with multiple serving backends such as vLLM and SGLang.
What do today’s prompts look like?
There is a rise of advanced prompts with the following properties:
Prompts are much longer than output: Today’s LLMs support context lengths as high as 10 million, and new LLM usages such as in-context learning, tool demonstration, and chain-of-thoughts keep emerging.
Prompt sharing is common: Sharing can come from different user requests needing the same tools or instructions to solve similar tasks, multiple questions on the same document, sequence of steps each using previous context, etc.
Some typical workloads with long and shared prompts include Tools and agents, virtual environments, Chain of thought, multi-modality QA, document QA, RAG, program generation, and few-shot learning. The diagram below displays how prompt growing and sharing happen as more requests arrive. The parts reused by multiple requests are highlighted.

Background and SOTA
Prefix Caching
With attention-based models, the intermediate computing result (KV cache) can be reused if sharing happens at the beginning of a sequence (i.e., prefix sharing). To exploit this property, an LLM serving system can store the KVs of a prompt and reuse its prefix when a match happens with a future request. Such reusing improves request response time and overall serving request rate.
Distributed LLM Serving
When scaling up a serving system, common techniques include data parallelism, model parallelism, and pipeline parallelism. While model and pipeline parallelism supports larger models by splitting a model across multiple GPUs, data parallelism increases the serving request rate by creating multiple instances of a model to process requests in parallel.
Existing systems
Most existing serving systems, such as vLLM, deepspeed-mii, and TGI, treat requests as independent. Additionally, most focus on optimizing output generation (decoding) and are unfit for today’s long prompt workloads. The diagram below illustrates how a serving system distributes requests across data-parallel GPUs without considering prompts. Requests of the same color have the same shared prefix.
Primitive Scheduling Strategies
Load-based, prefix-agnostic scheduling (Exploration): Today’s LLM serving systems distribute requests across data-parallel GPU instances to balance their loads, using techniques such as Round robin and least outstanding requests. This approach allows for all GPUs to be equally and fully utilized but results in more KV recomputation.
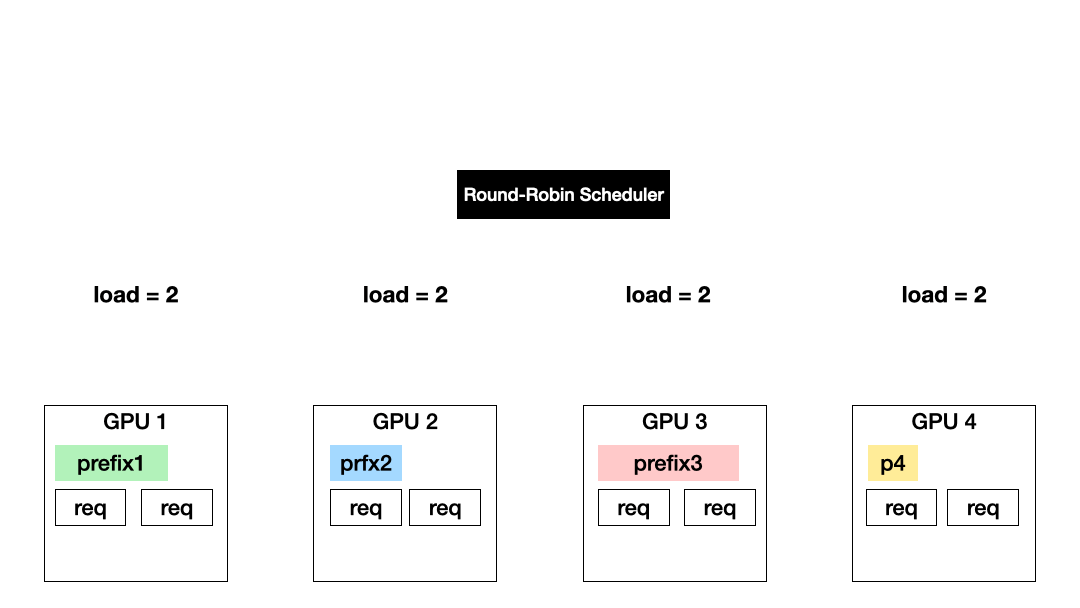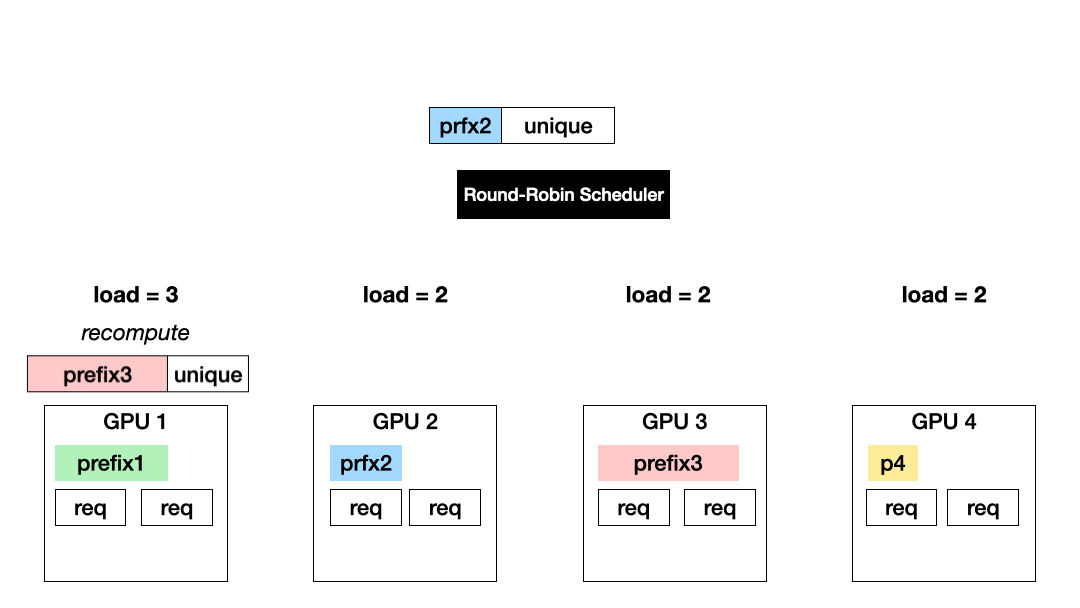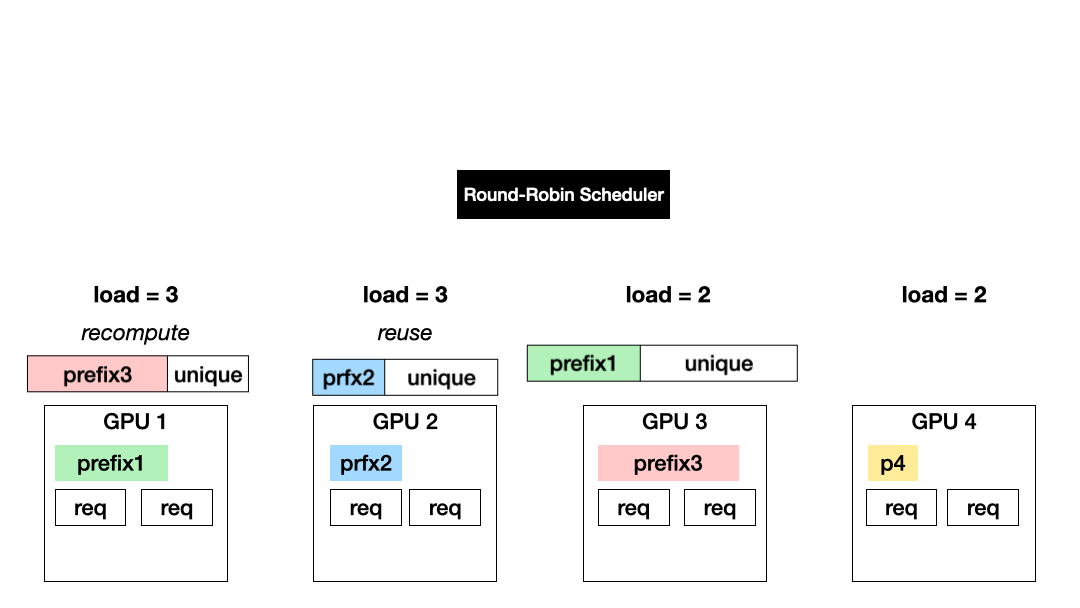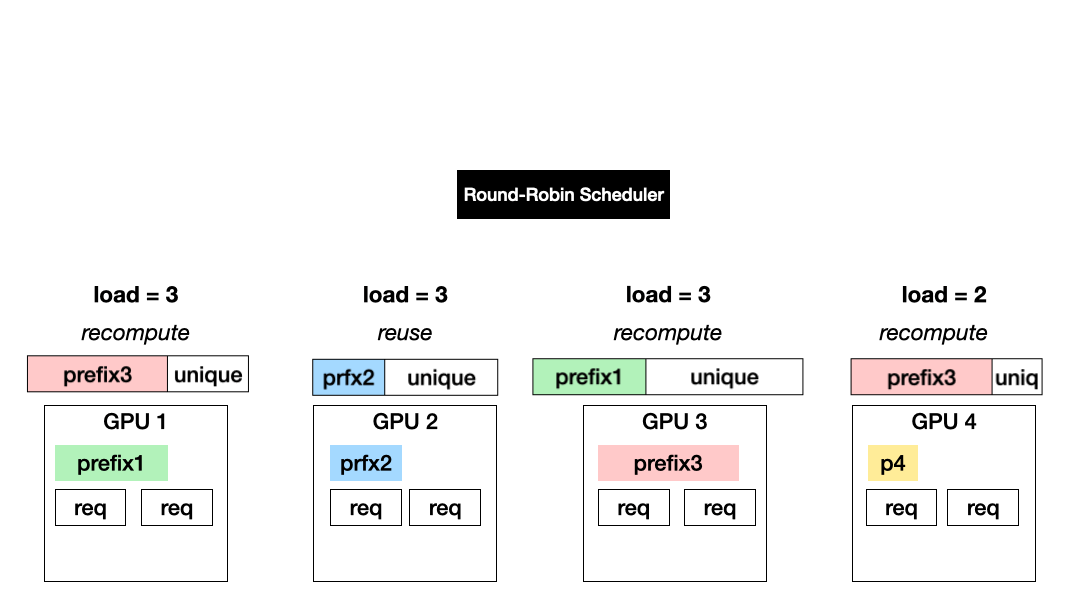
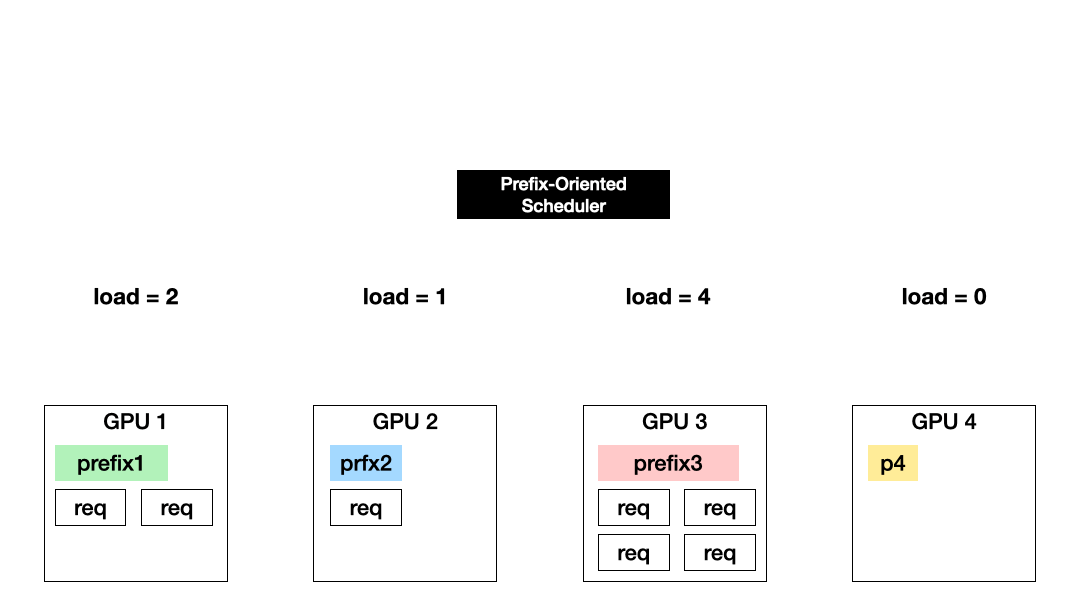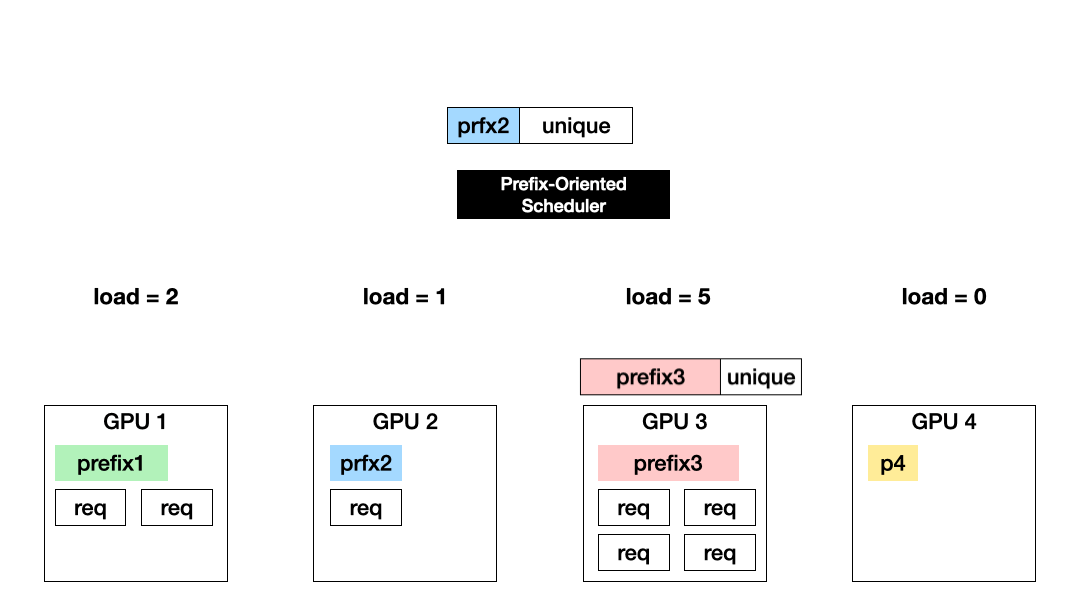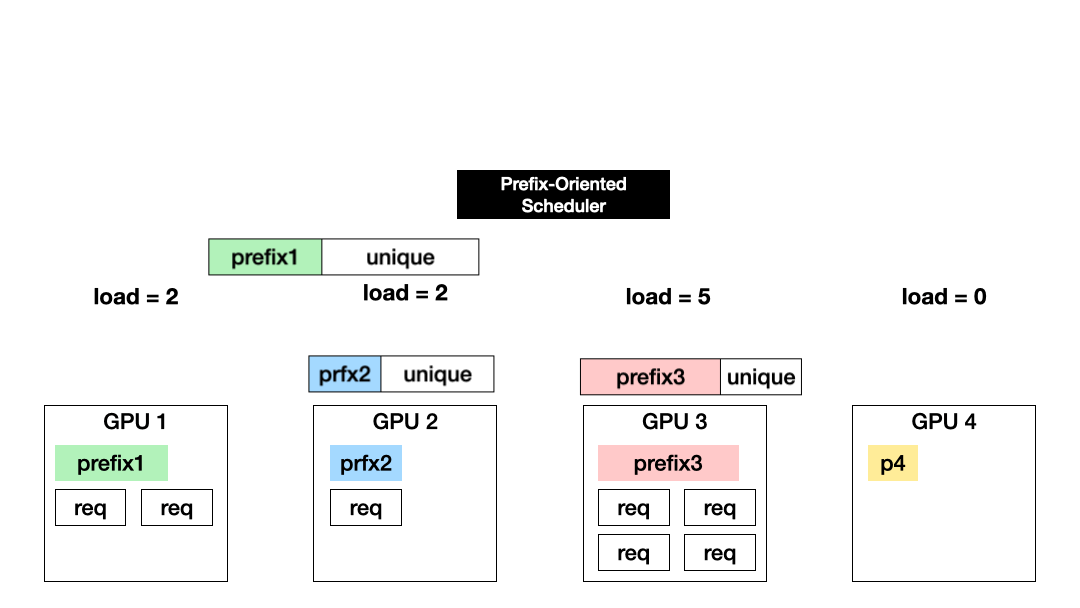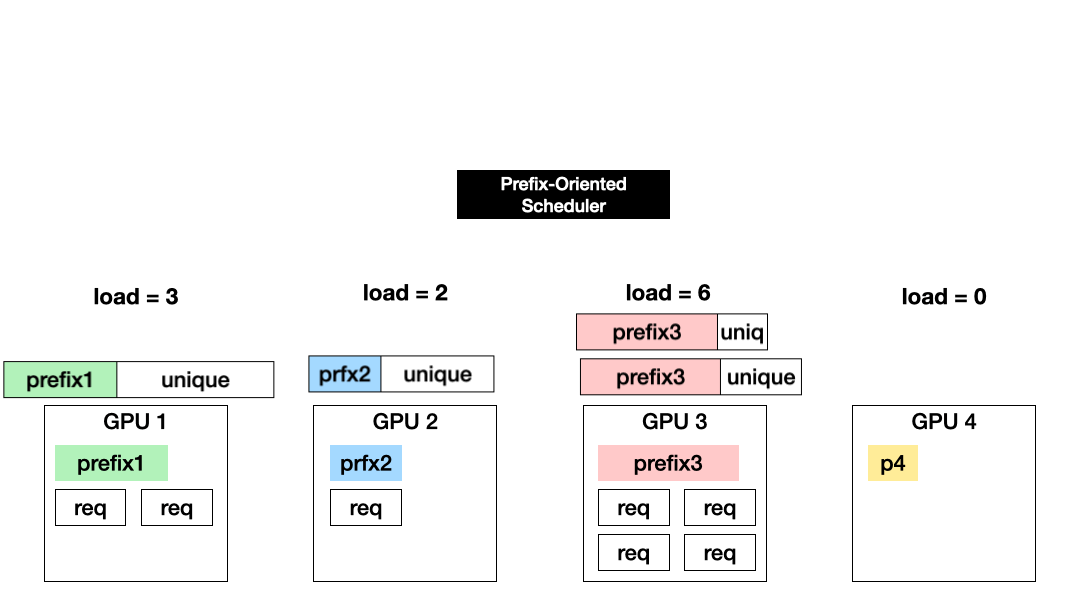
Prefix-based, load-agnostic scheduling (Exploitation): Another approach is to schedule a request to the GPU with the KV of the longest prefix match. This approach maximizes the exploitation of computed KV cache but could cause imbalanced GPU utilization.
E2 Scheduling: Efficient Scheduling for Long and Shared Prompts
E2 Scheduling (Exploitation + Exploration) combines the benefits of exploration and exploitation by dynamically choosing between them for each request. Specifically, E2 chooses exploitation when the GPU computation saved from reusing a shared prefix is larger than the recomputation cost of exploring a GPU without sharing. This happens when the shared prefix of a prompt is longer than its remaining part.
We use the following cost function in order to make an efficient scheduling decision
- Load Cost(L): Estimated total request load on GPU-i at the time of and after running the current request
- Eviction Cost(E): Load on GPU-i to evict to make room for running the current request
- Running Cost(R): Cost to run the current request on GPU-i
Furthermore, to accommodate load changes after the initial assignment of a KV cache and inaccuracy in the above cost estimation, Preble detects load imbalance across GPUs and adapts request placement accordingly.
Preble Architecture
When a request arrives, Preble first tokenizes the request and then sends it to Preble’s global scheduler. The global scheduler maintains a prefix tree representing all cached prefixes in the cluster and per-GPU load distributions. It uses these sets of information to apply the E2 scheduling algorithm. If an imbalance load is detected, the global scheduler adjusts its placement policy accordingly. After the global scheduler sends a request to a GPU, a GPU-local scheduler inserts it into a local waiting queue that is sorted based on fairness and cache reusing considerations. After a request finishes or when a local GPU evicts a cached KV, it informs the global scheduler to update the maintained information.
Evaluating the effectiveness of Preble
We evaluated Preble across five workloads, two LLMs (Mistral 7B & LLama-3 70B), and two GPU clusters (NVidia A6000 and H100). Results, as shown below, reflect Preble’s consistent improvement (1.5-10x average and 2-14x p99 latency reduction) over SGLang (a SOTA serving system that performs prefix caching but no distributed load consideration) and an optimally balanced load scheme.

See our technical report for more detailed experiment results.
Preble also improves performance on all metrics over SGLang with a mixed workload on a real LLM request trace.

See our paper for more detailed experiment results, such as the comparison to VLLM and an ablation study.
Acknowledgement
We’d like to thank Junda Chen, Yutong Huang, Ryan Kosta, Nishit Pandya, Max Hopkins, and Geoff Voelker for providing feedback and their advice.
This material is based upon work supported by gifts from AWS, Google, and Meta. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of these institutions.
Citation
@inproceedings{srivatsa2024preble,
title="{Preble: Efficient Distributed Prompt Scheduling for LLM Serving}",
author={Vikranth Srivatsa and Zijian He and Reyna Abhyankar and Dongming Li and Yiying Zhang},
booktitle={Proceedings of the Forty-First International Conference on Machine Learning (ICML'25)},
year={2025},
month=Jul,
address={Singapore},
}
Arxiv URL: https://arxiv.org/abs/2407.00023
Preble is ready to install/run at https://github.com/WukLab/preble
pip3 install preble
preble run sglang/vllm –port XXX –model XXX