Author: Reyna Abhyankar, Qi Qi, Yiying Zhang
AI Agents: Smart, But Slow
Computer-Use Agents (CUAs) can perform complex tasks, but their high latency makes them impractical. A task that takes a human just 2 minutes to complete can take an agent over 20 minutes. We study these bottlenecks and construct a new benchmark, OSWorld-Human, that measures both accuracy and temporal efficiency of CUAs.
For a typical task
For the same task
We conduct a deep dive on the primary causes of CUA latency by studying Agent S2, the leading open-source CUA based on the OSWorld benchmark. The S2 framework generally follows the “observation-think-act” framework, as depicted for a simple document editing task here:
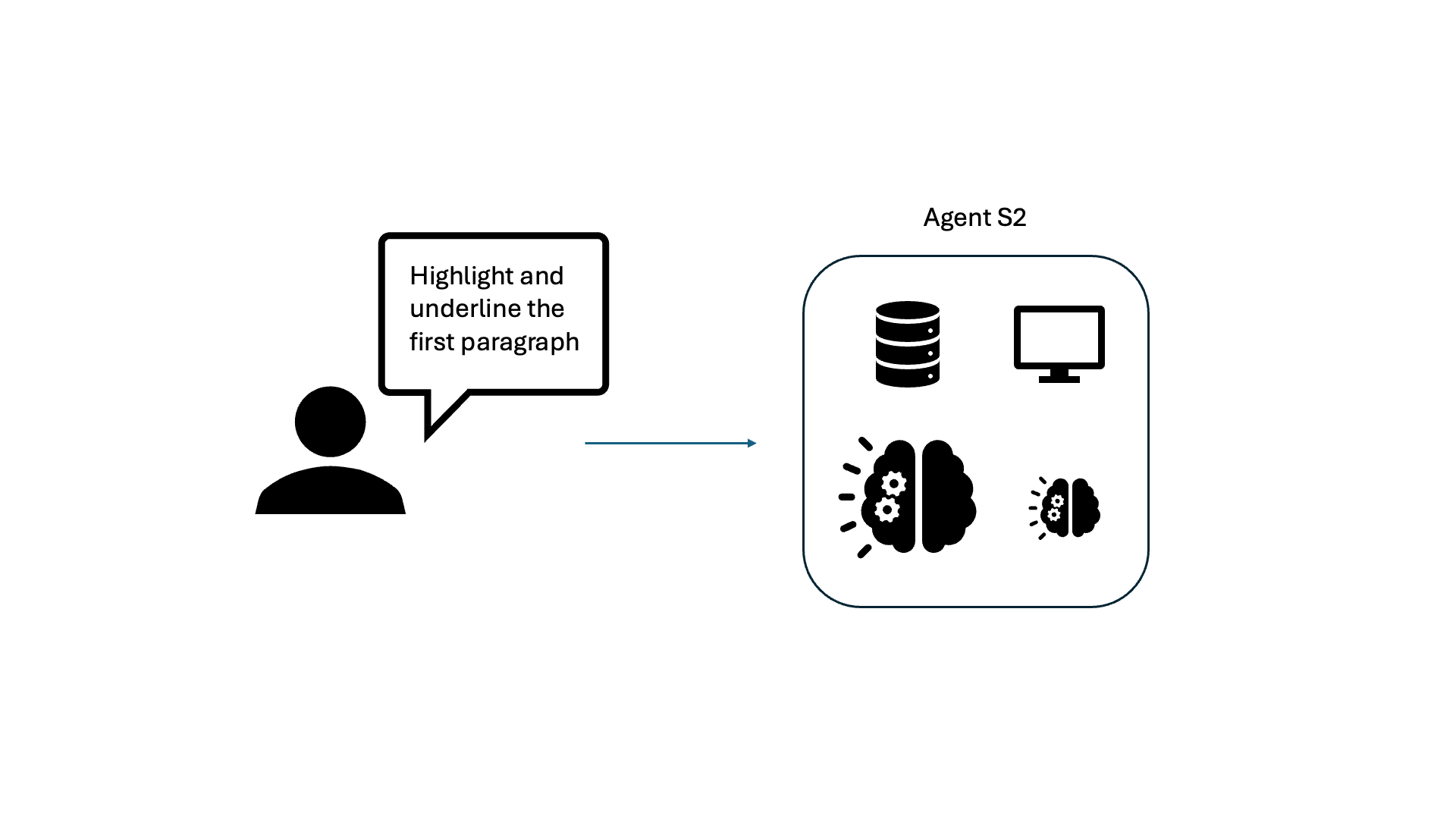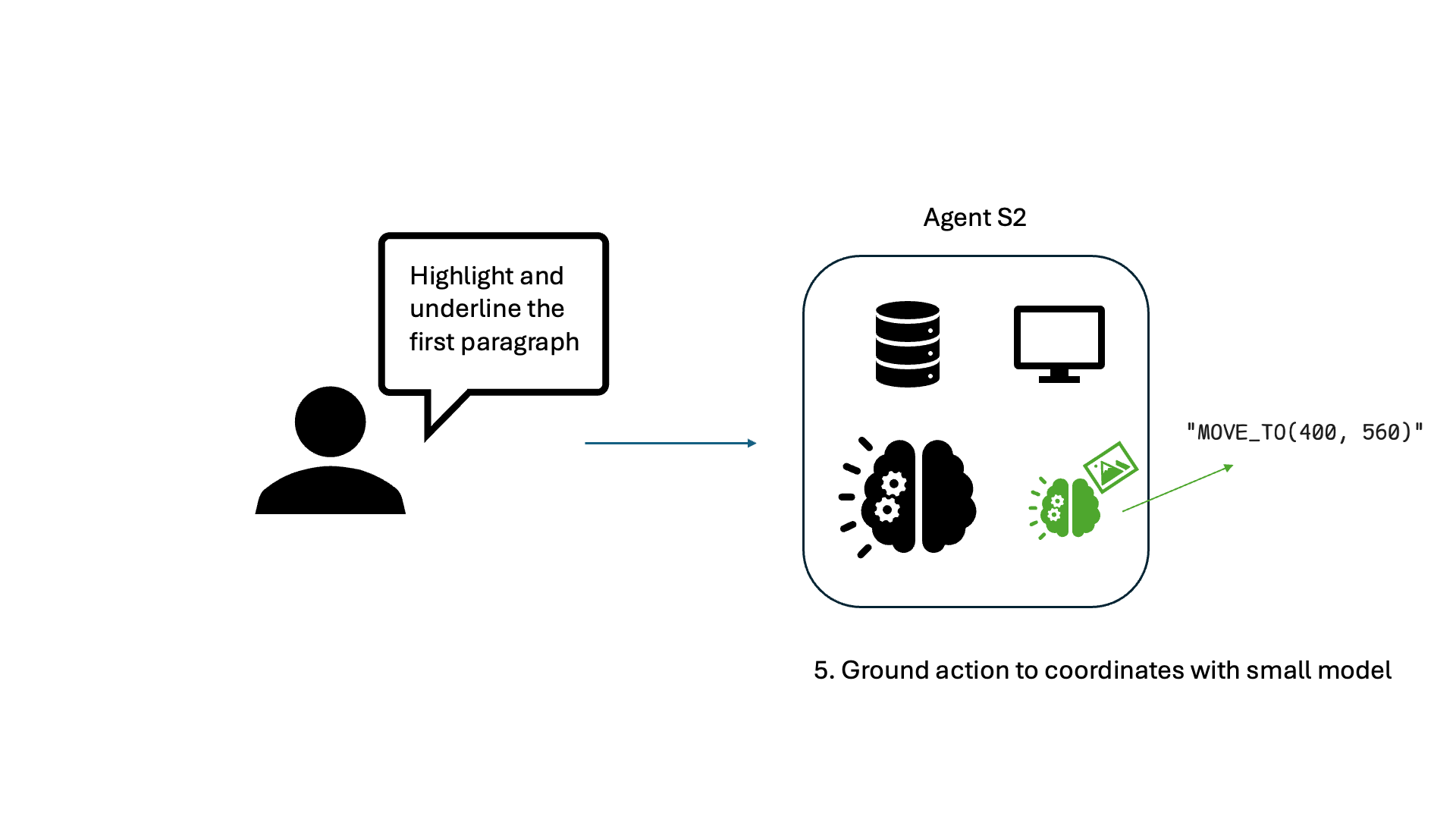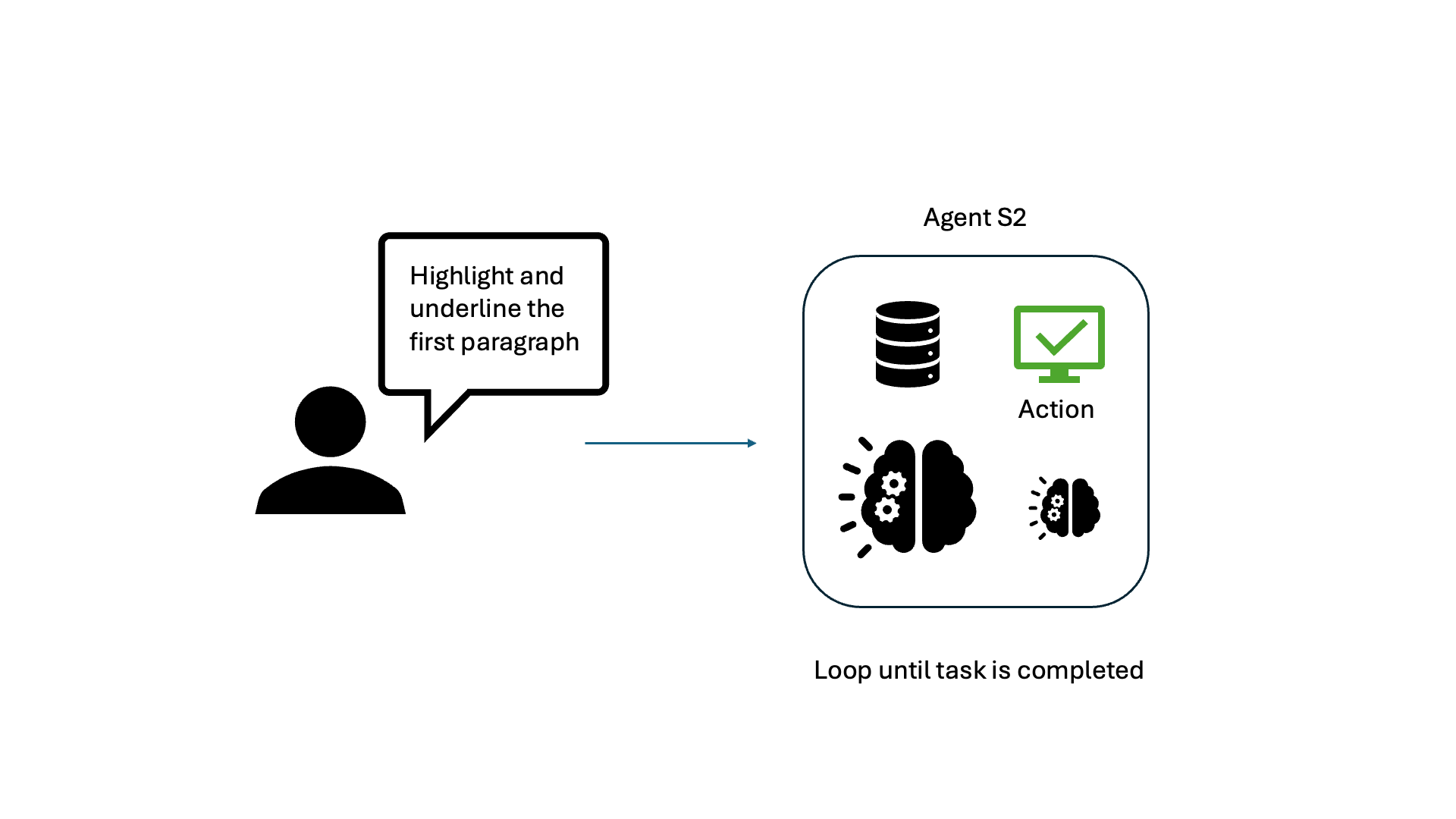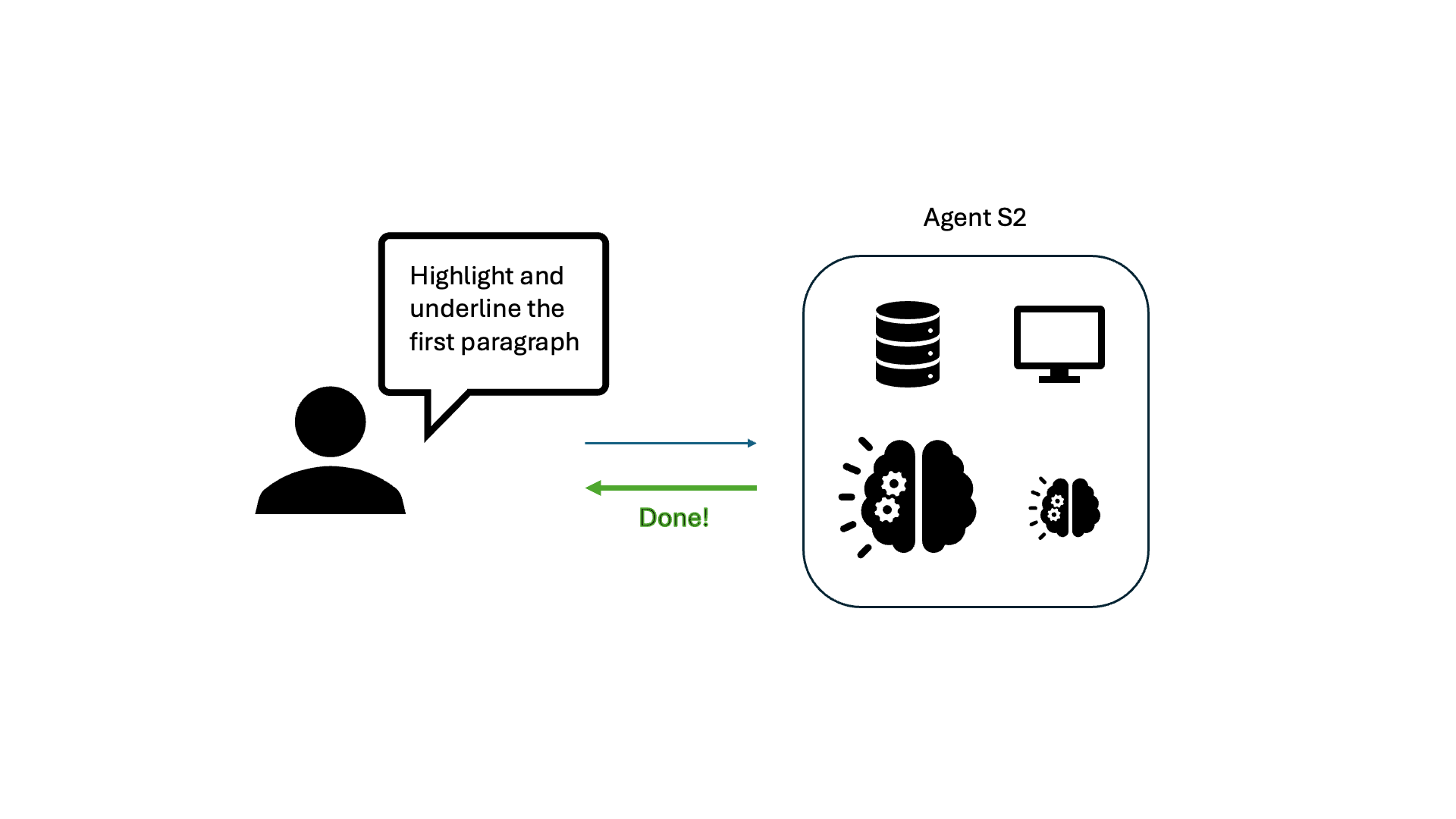
Upon breaking down the latency for various applications, LLM calls for “Planning” and “Reflection” are the main culprits, consuming 75-94% of total task time. Planning and reflection occur at each step and include the full history of observations. This means tasks that take more steps are quadratically slower than tasks that take fewer steps.
Application Action Breakdown
OSWorld-Human: A New Benchmark
Based on our observations, we constructed OSWorld-Human, a benchmark that reflects how humans accomplish computer-use tasks. We manually performed all 369 tasks in OSWorld and recorded the sequence of manual actions needed to complete them. OSWorld-Human is available open-source.
Furthermore, we found that some steps can be completed without the need of an additional screenshot since there is no change in the UI. For example, clicking on a text box, typing, and pressing enter do not require 3 separate screenshots. Hence, we also construct a grouped-action trajectory for each task, which represents actions that can be completed from a single observation. Applications where the UI does not change significantly from step to step have a much higher discrepancy between single and grouped trajectories, as shown below.
Application Actions: Single vs. Grouped
To measure the performance of SOTA agents on OSWorld-Human, we introduce two weighted efficiency scores, WES+ and WES-, which weight the agent’s accuracy by its efficiency.
Successful Task: $r_t = 1$
A higher score is awarded for using fewer agent steps ($t_{\text{agent}}$) relative to the expected human steps ($t_{\text{human}}$).
Failed Task: $r_t = 0$
A smaller penalty is assigned for failing in fewer agent steps ($t_{\text{agent}}$) relative to the maximum steps allowed ($S$).
We analyze 16 agents’ performance on OSWorld and OSWorld-Human against the original success rate on OSWorld on 3 metrics: single-action WES+, grouped-action WES+, and WES- (computed the same for single and grouped). Even the highest-performing agent, S2, takes 1.4x more steps than needed to complete a task, which can add tens of minutes of real-time latency.
Our Vision
CUAs can significantly boost human productivity and accessibility by automating desktop tasks. Their adoption hinges on bringing latency down to human or sub-human levels. We hope OSWorld-Human encourages future research on improving the efficiency of CUAs as a parallel goal to accuracy.