Efficient Augmented LLM Serving With InferCept
Author: Reyna Abhyankar and Yiying Zhang
TLDR: Today’s large language models (LLMs) are being paired with various tools and environments to satisfy increasingly complex user queries. Augmenting models with these capabilities means LLM inference can be intercepted by external actions. We designed InferCept [ICML ‘24], the first serving framework designed for augmented LLMs. InferCept minimizes resource waste and sustains a 1.6x-2x higher serving load, completing twice as many requests compared to state-of-the-art serving systems. Try InferCept here.
LLMs Today Are Augmented with External Tools and Environments
To broaden the capabilities of LLMs to handle more diverse tasks, there’s a growing trend of augmenting LLMs with external tools and real-time interactions, such as ChatGPT plugins, non-language models, math tools, and virtual environments. With fine tuning or prompt demonstration, LLMs can generate the triggering of an appropriate augmentation. When that happens, the LLM output generation is paused. We refer to all such non-LLM usages as “interceptions,” as they essentially intercept normal LLM generation.

The workflow of LLMs with interception, as shown in the figure above, is as follows:
- LLM generates tokens that trigger a particular tool, environment, or another model (an “augmentation”).
- The serving system waits for a response while the query is dispatched to the augmentation.
- When augmentation finishes with a returned response, the serving system appends the response to the sequence generated so far and continues normal generation.
We study the behavior of six different augmentations, including a calculator API, a wikipedia API, a stable diffusion model, a text-to-speech model, an embodied agent in a virtual environment, and a chatbot (where the user providing follow-ups is the augmentation). We find that a given user’s request can be intercepted frequently, ranging on average from just 3 times to as high as 28 times. The execution times also vary greatly depending on the augmentation. Tools like calculators are very fast, returning in less than 1 second. Machine learning models such as text-to-speech and stable diffusion can take 20x longer. The next-generation augmented LLM systems should account for all of these possibilities.
Today’s Techniques to Handle Interceptions
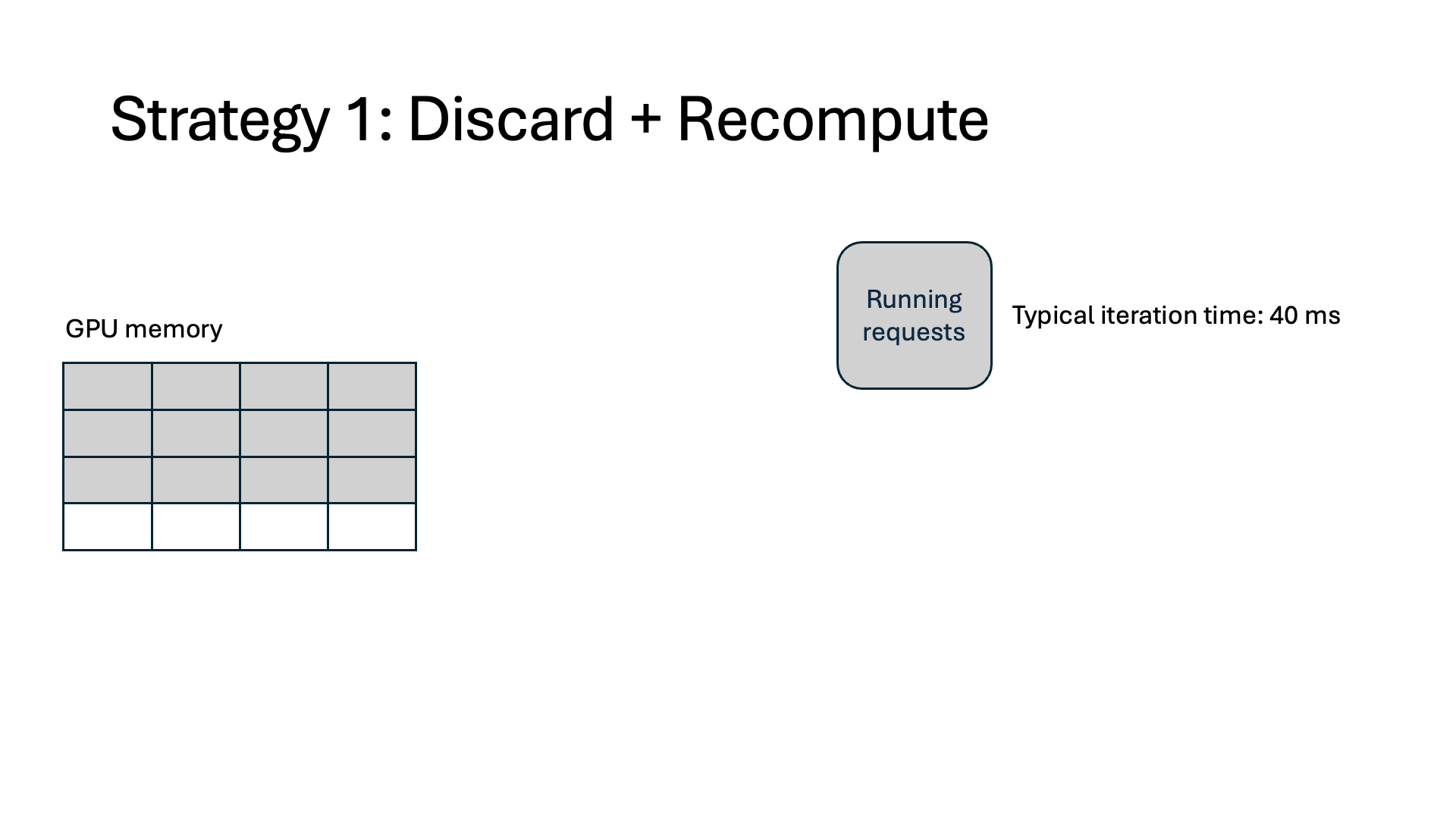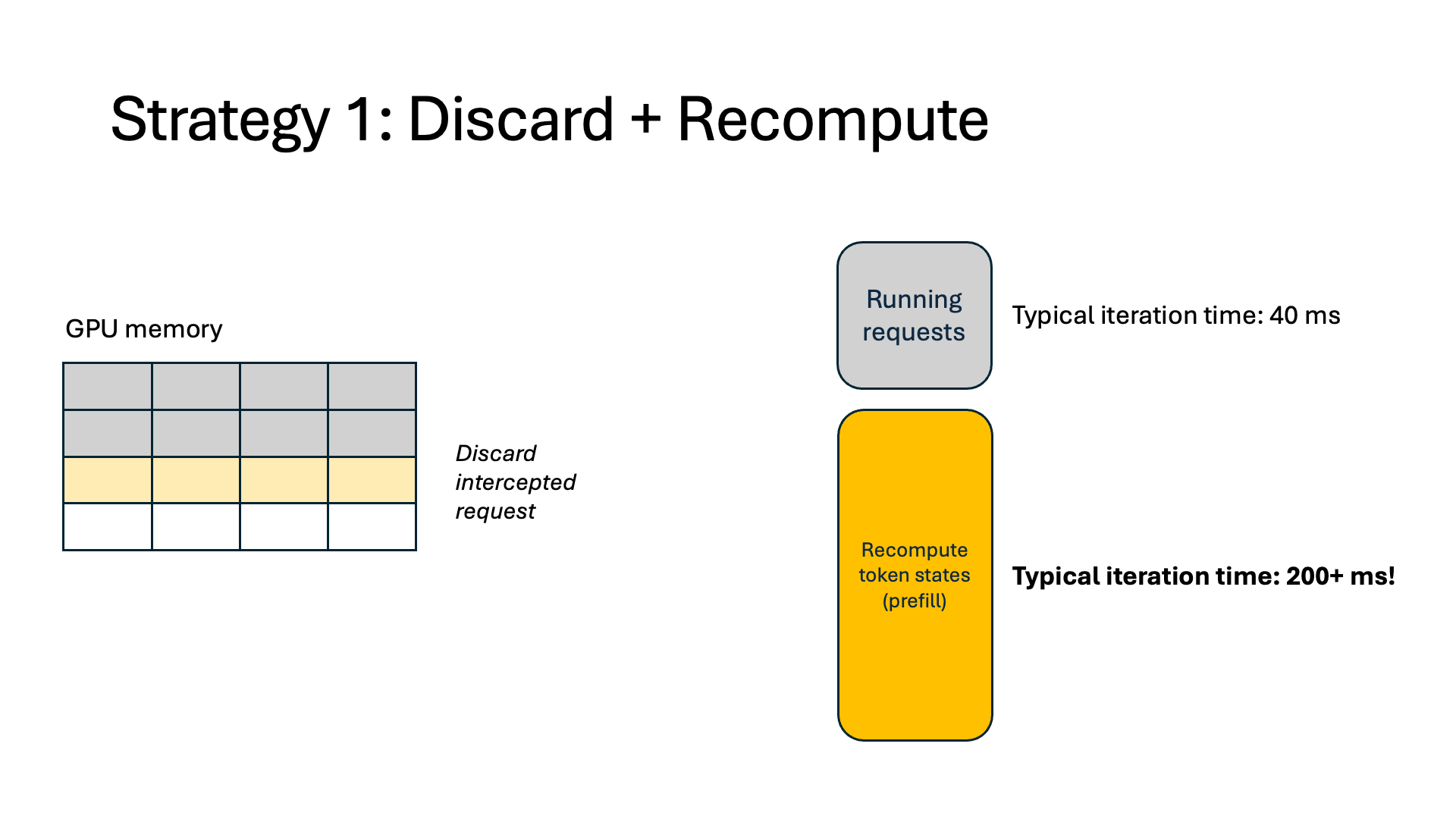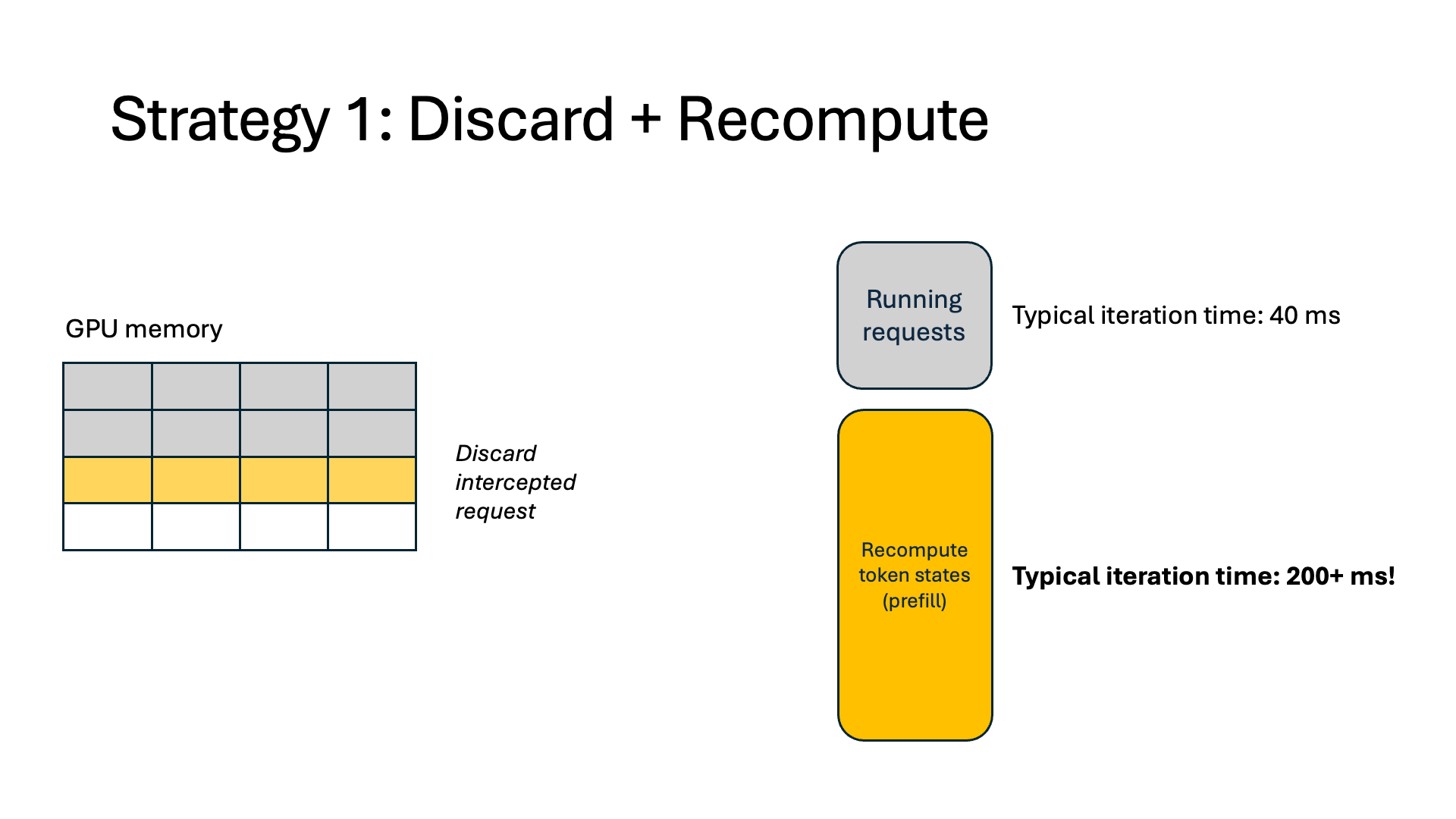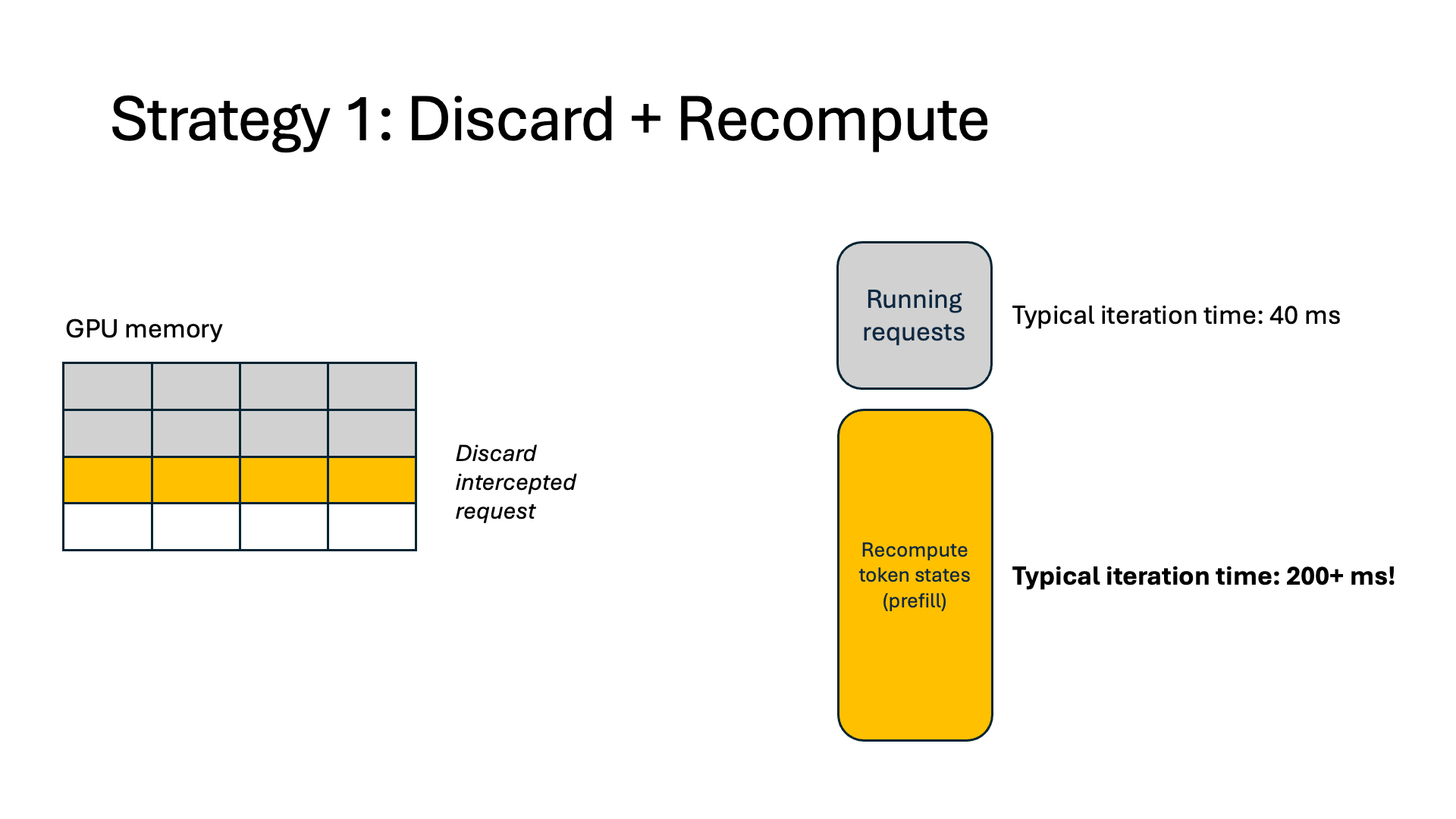
When a request is intercepted, current systems (vLLM) evict all token states (i.e., its cached K and V vectors generated during the attention computation) for that request. When the augmentation finishes, today’s systems recompute the KV for the entire sequence before the interception and then continue with normal output generation. Because of this, a typical model forward pass can take over 5x longer in the prefill stage. Our measurements show that 37% of end-to-end execution time is spent recomputing KVs, and as a result, 27% of GPU memory is wasted.
There are three potential techniques to deal with interceptions.
- Discard. This is today’s inference systems approach, as described above.
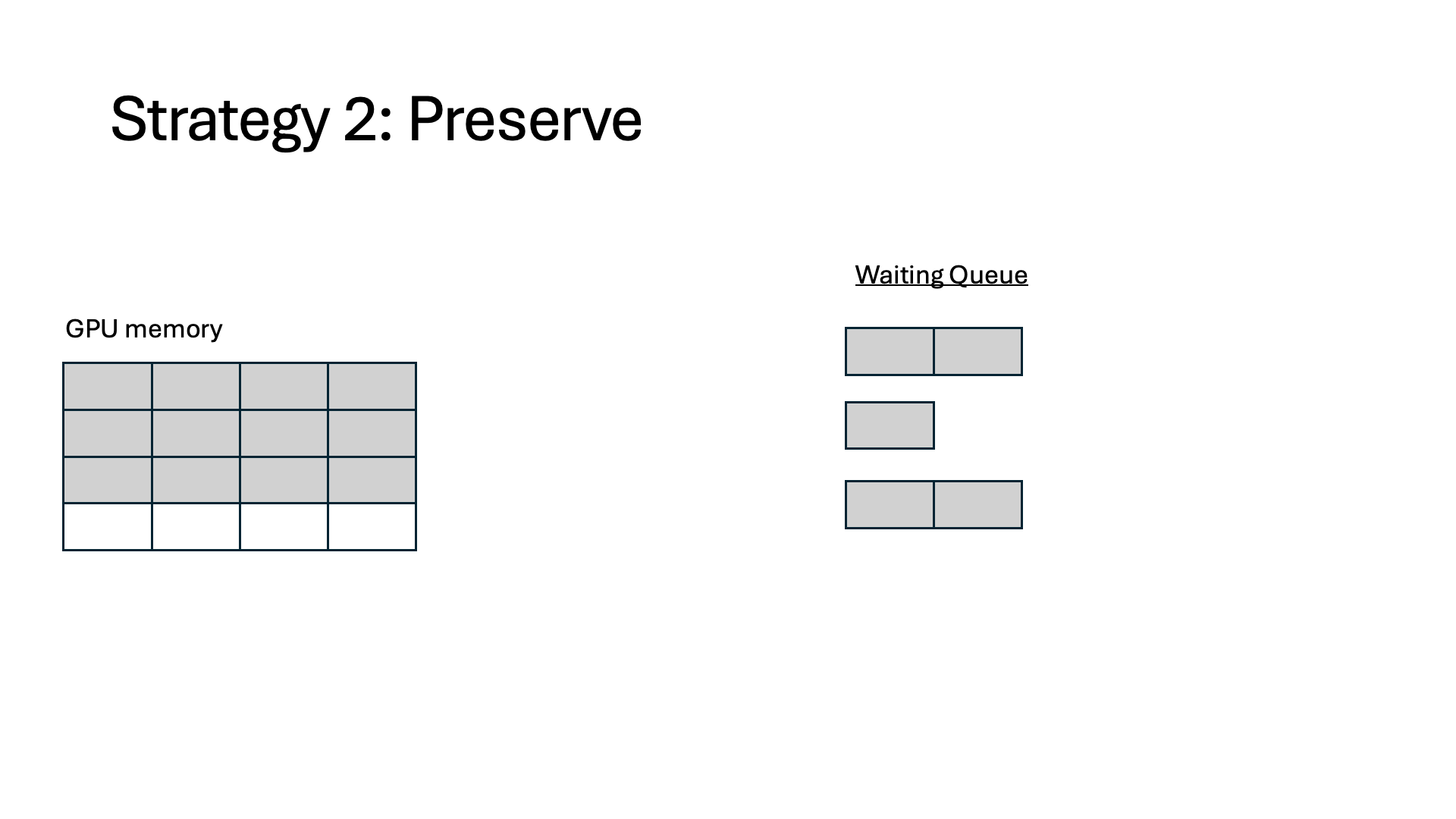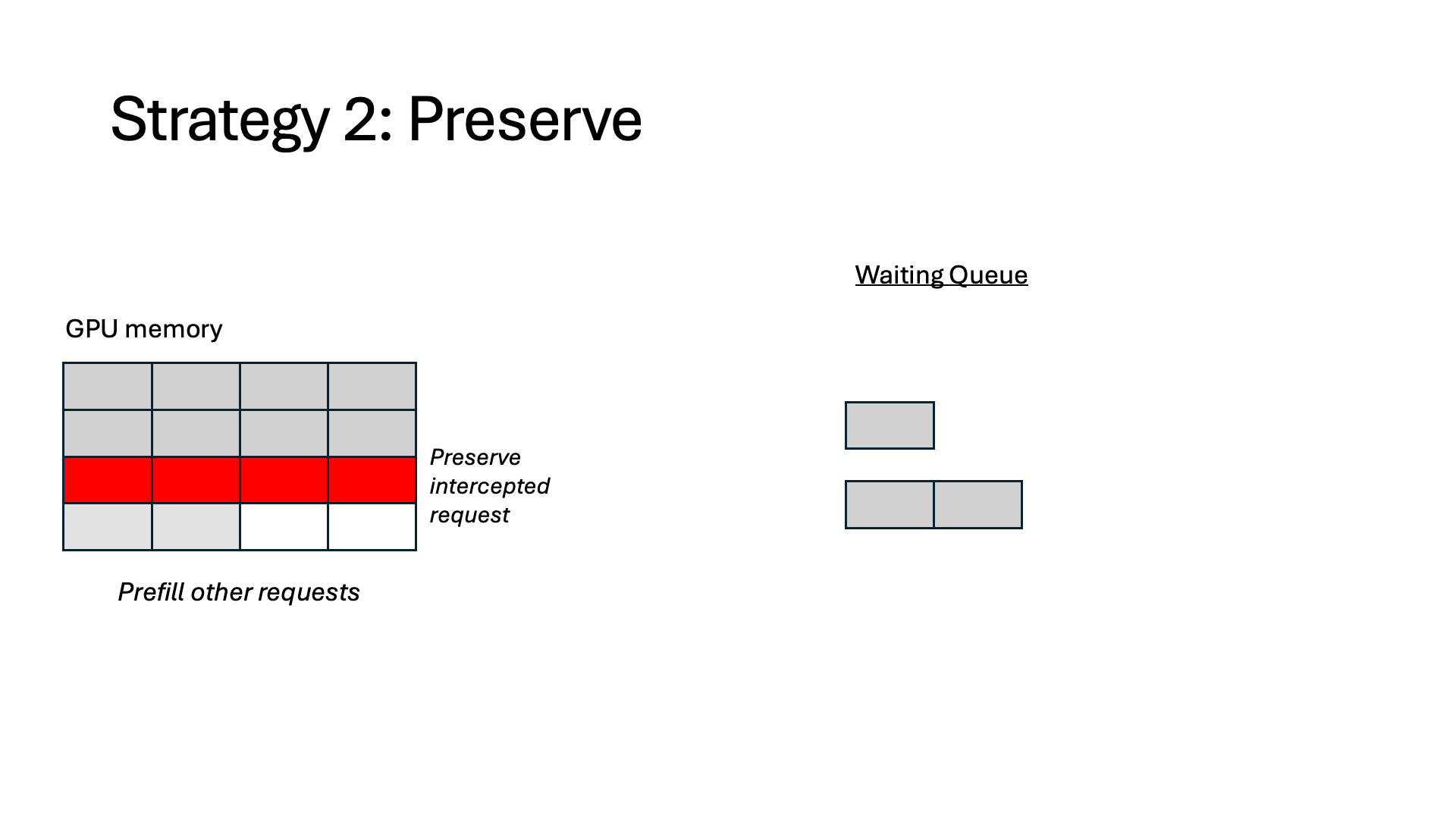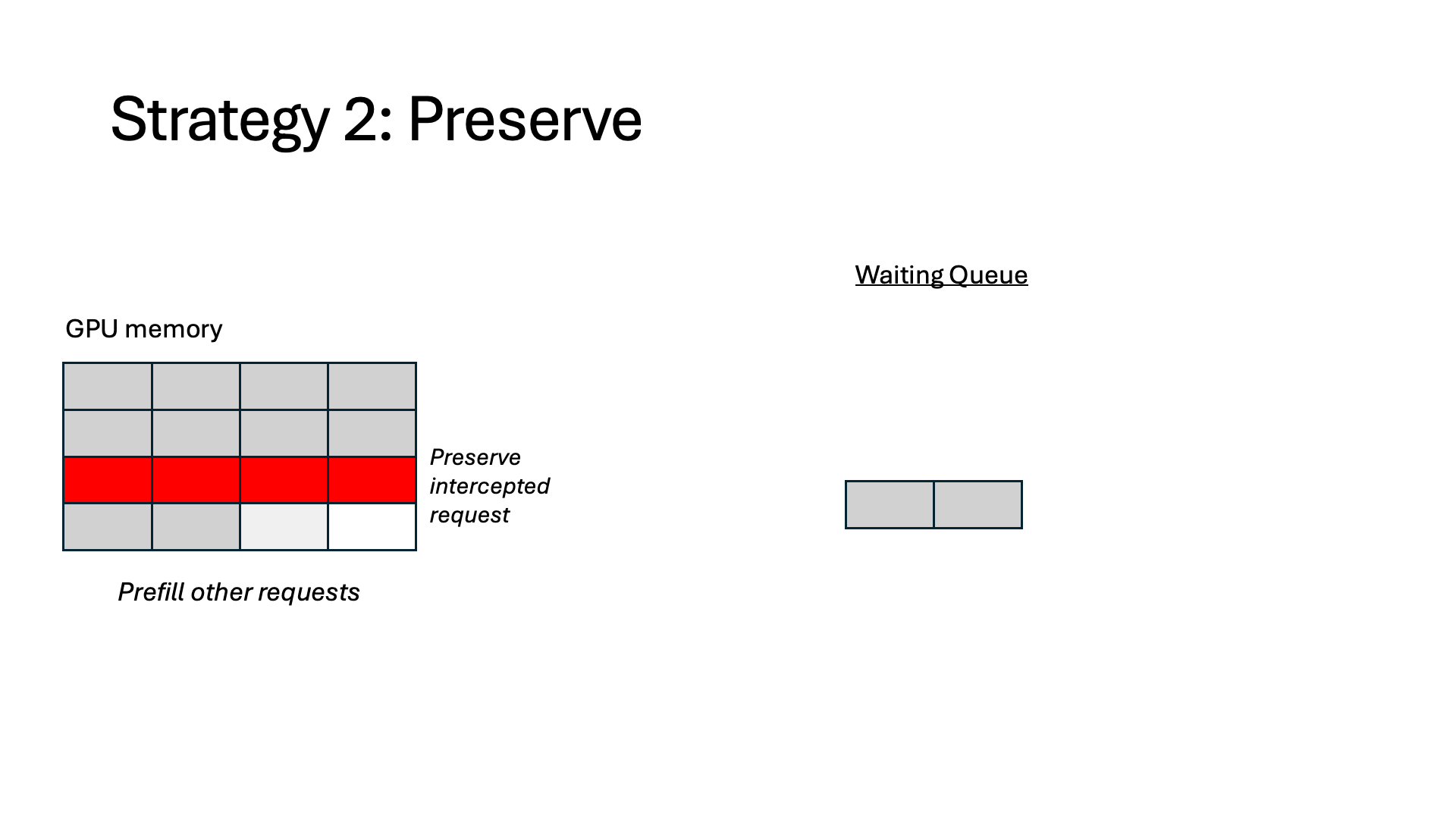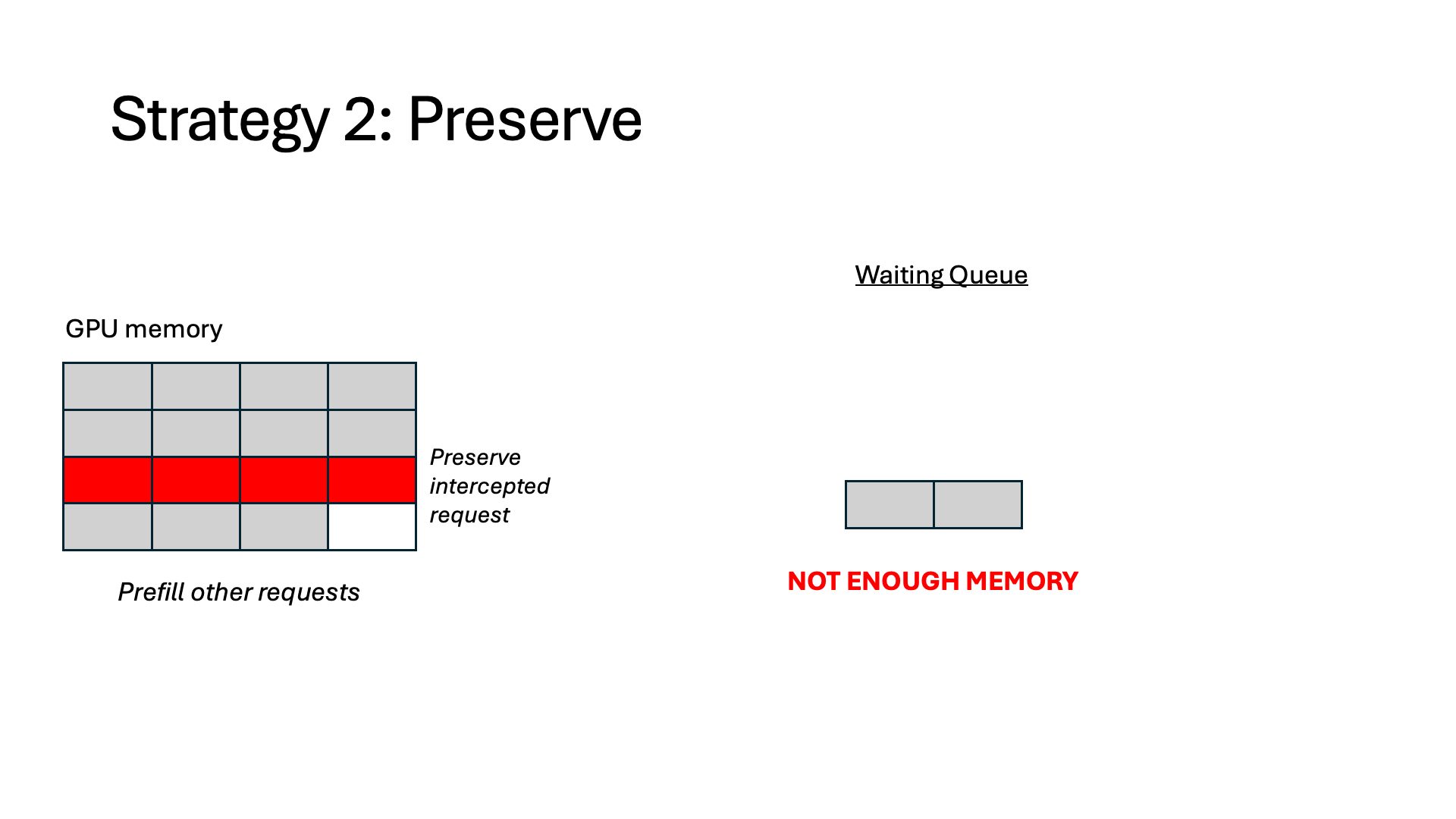
- Preserve. The token states are preserved in GPU memory and wait for the interception to finish, at which point it can resume immediately without any recomputation. However, the preserved memory is unusable for other requests for the duration of the interception.
- Swap. We can swap token states out to CPU memory, such as in offloading-based systems. This alleviates the need for recomputation and frees up memory on the GPU, but those token states must be swapped in when the interception finishes. Swapping can stall other running requests because the amount of data being swapped often greatly exceeds the limited CPU-GPU bandwidth.
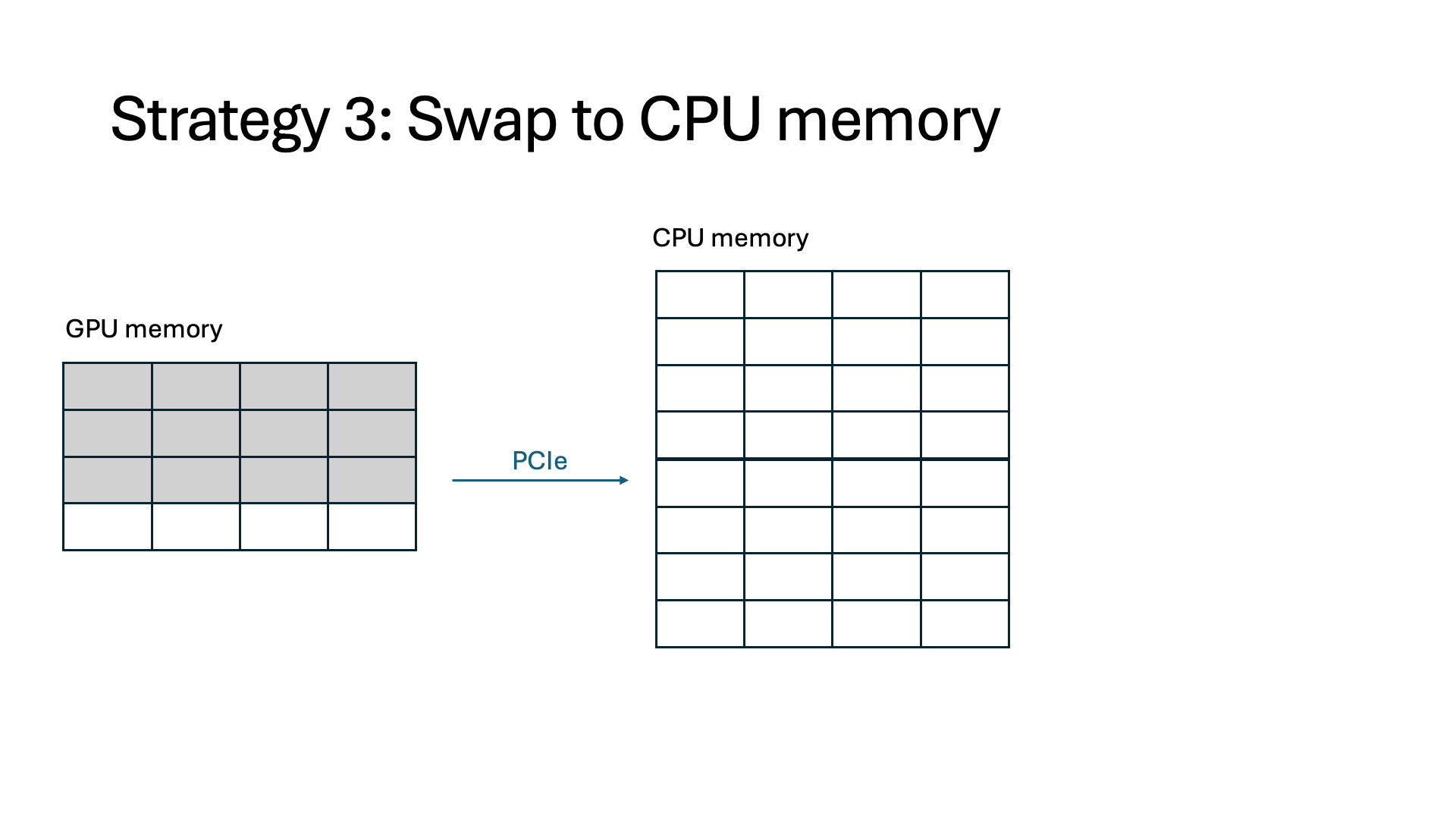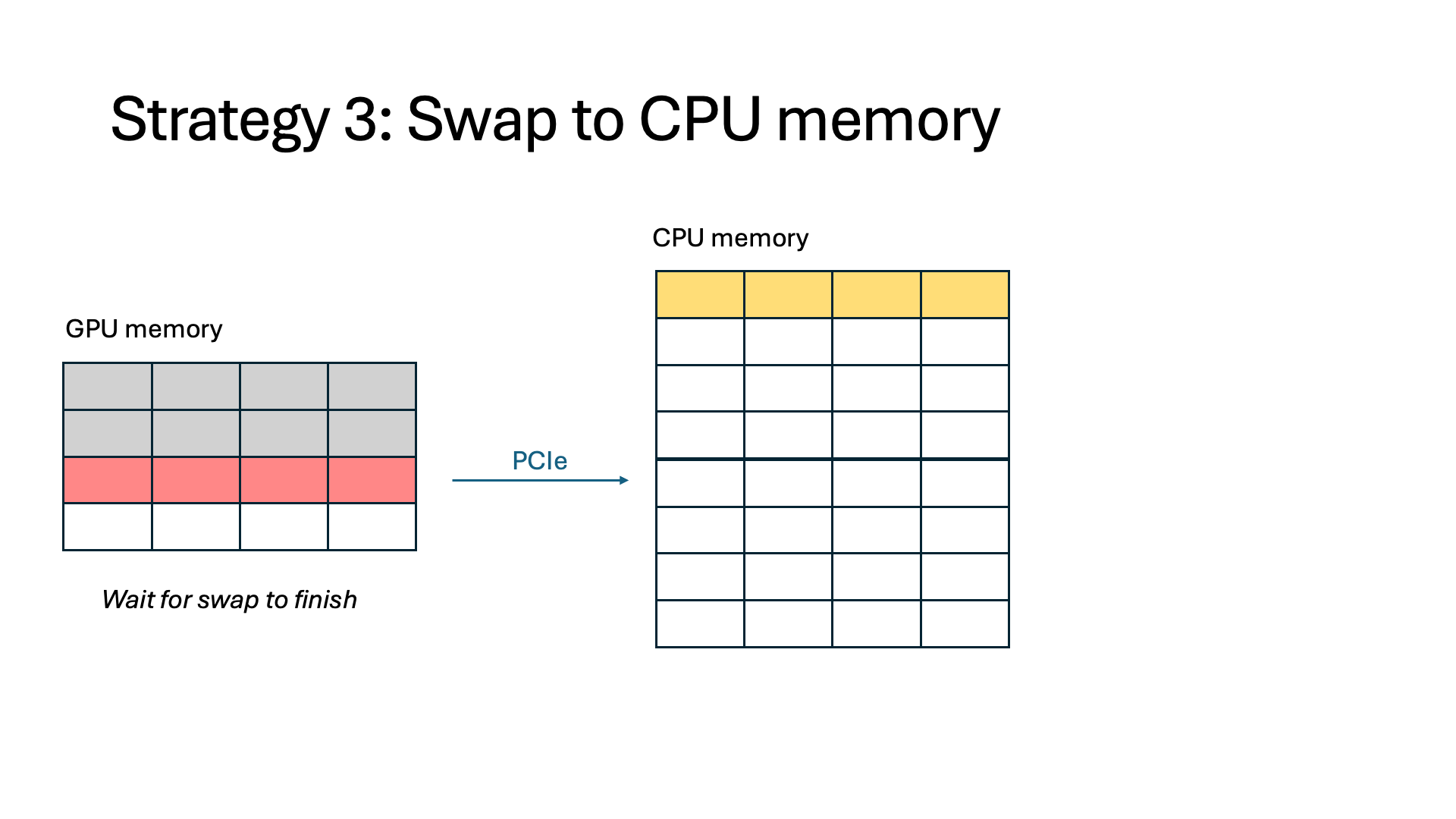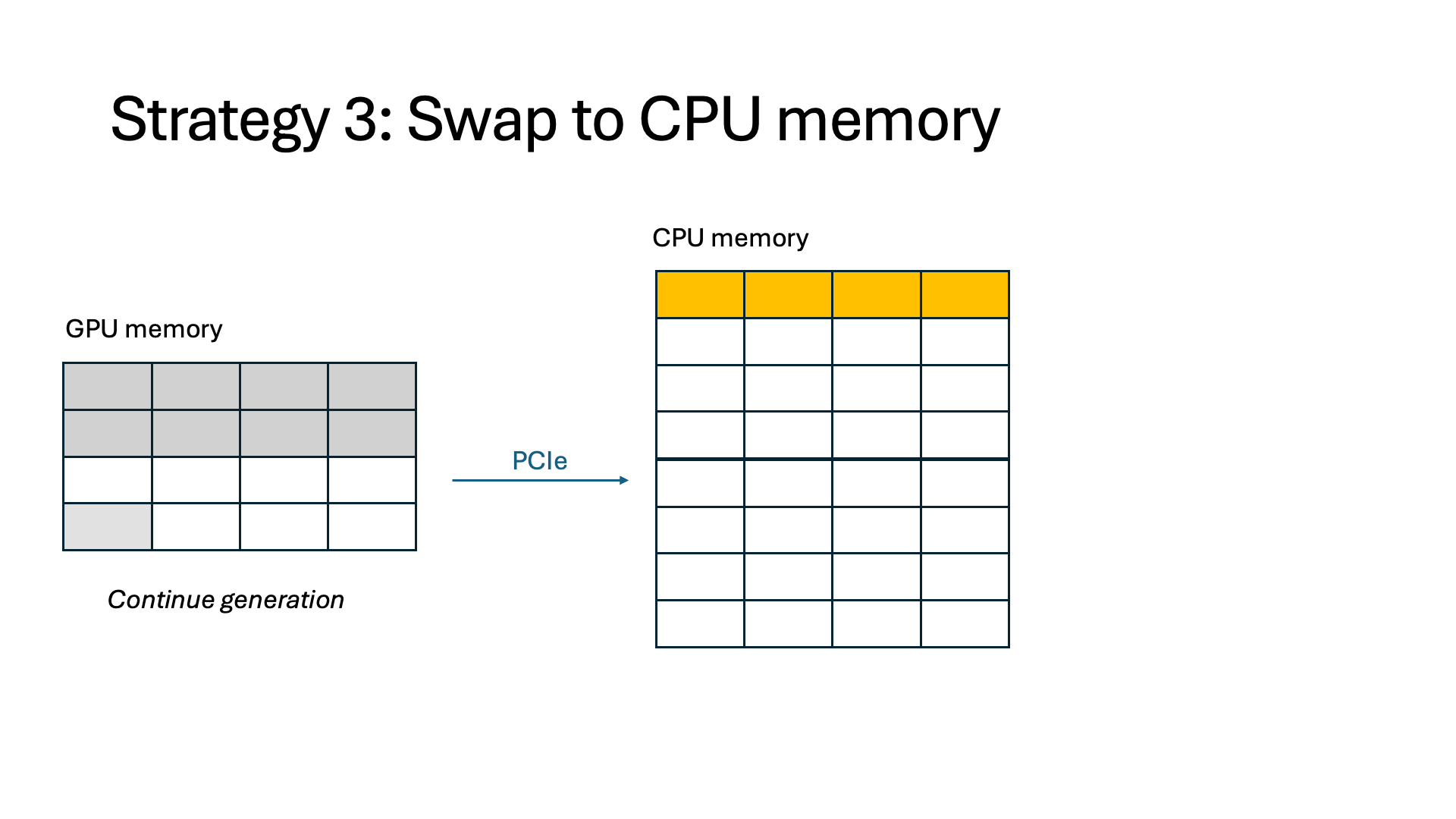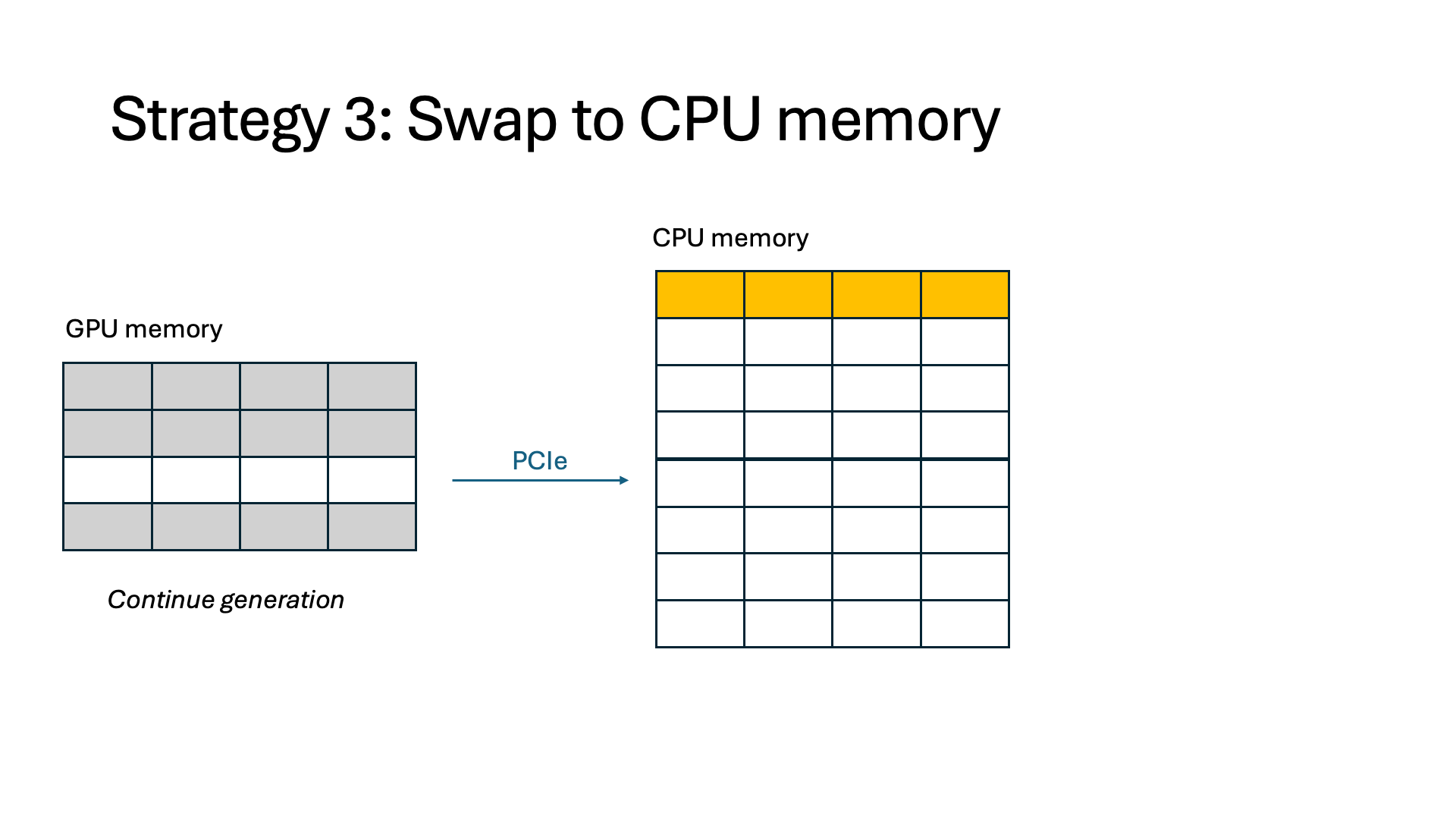
Introducing InferCept
InferCept efficiently handles LLM interceptions with three steps:
- Quantifying GPU memory waste
- Improving existing techniques individually
- Scheduling requests to minimize GPU memory waste
Quantifying GPU memory waste
The key idea behind InferCept is to minimize the memory waste caused by interceptions. We treat memory waste as the amount of unused memory * duration it is unused. Within this framework, we can introduce a formula for computing the waste associated with each technique, yielding a WasteDiscard, WastePreserve, and WasteSwap value for each intercepted request. A caveat is that the waste terms should consider not only the intercepted request but also other running requests that are impacted (e.g., other running requests, which are waiting for recomputation to finish, waste the memory they occupy).
Improving existing techniques
For WasteDiscard and WasteSwap, we pipeline the recomputation and swapping out and in for increased throughput. For the former, we chunk the context sequence into multiple segments and recompute one at an iteration, so that each iteration’s GPU computation resource is fully utilized but not exceeded. As a result, no other running requests are stalled because of recomputation.
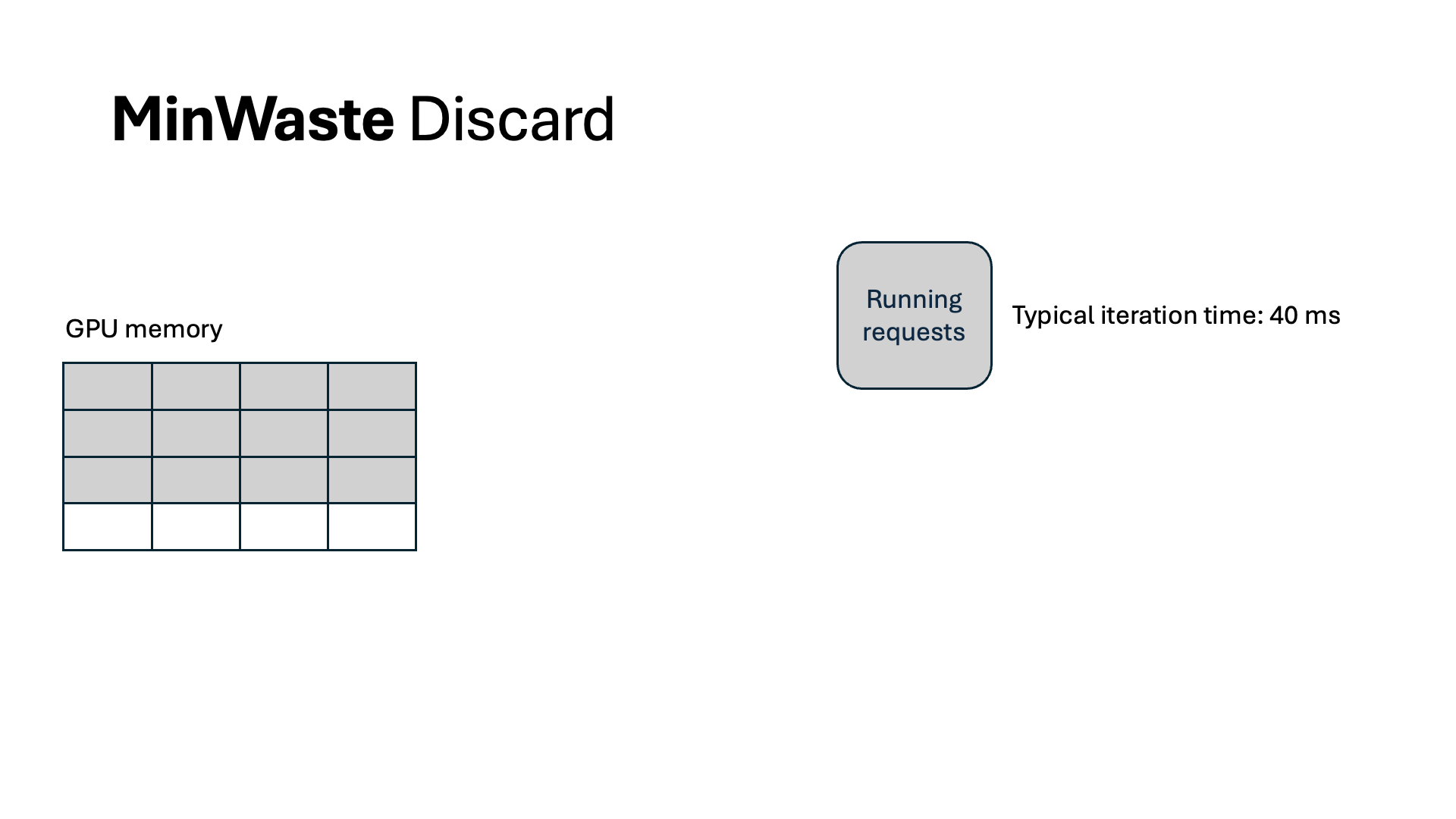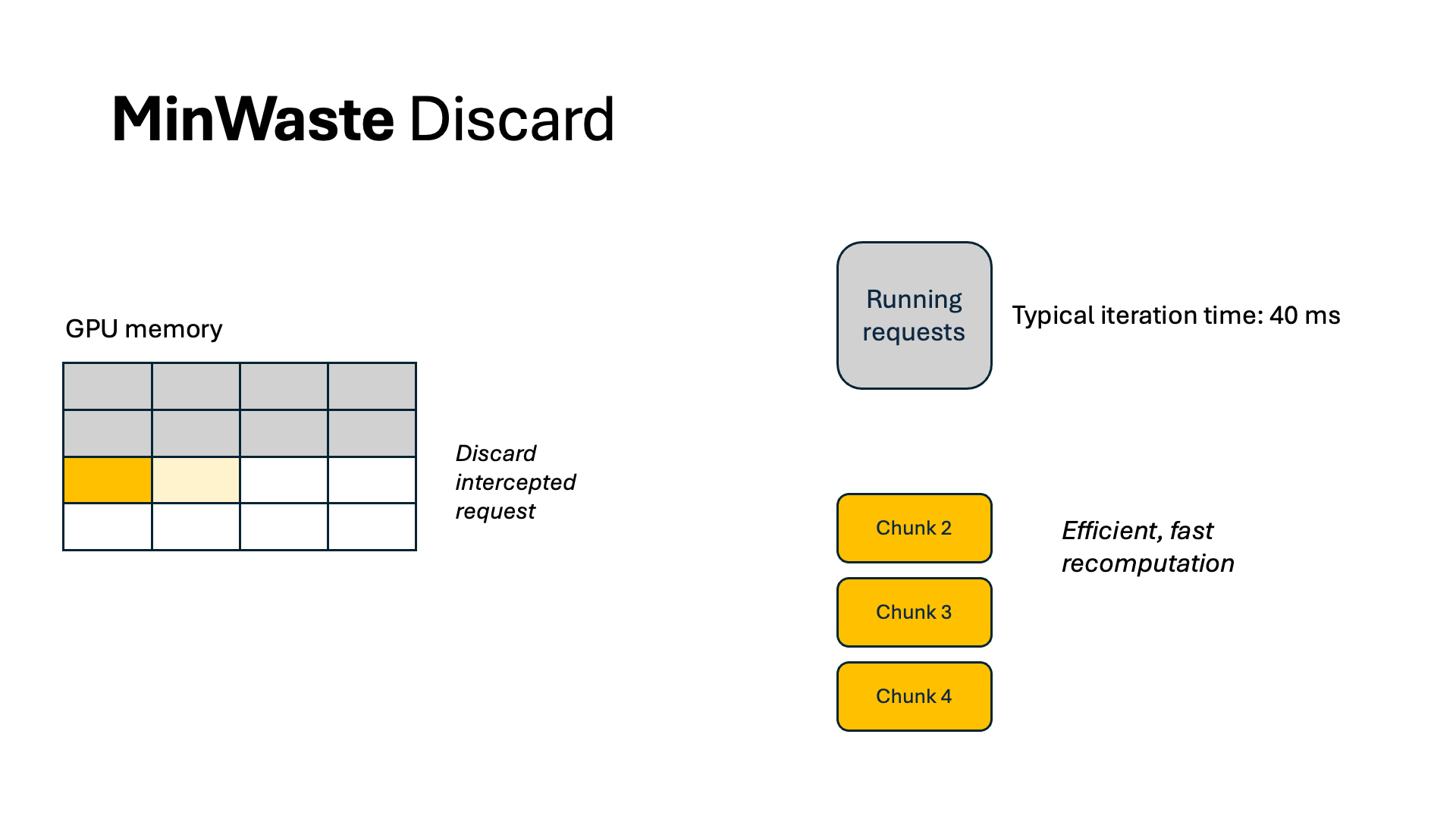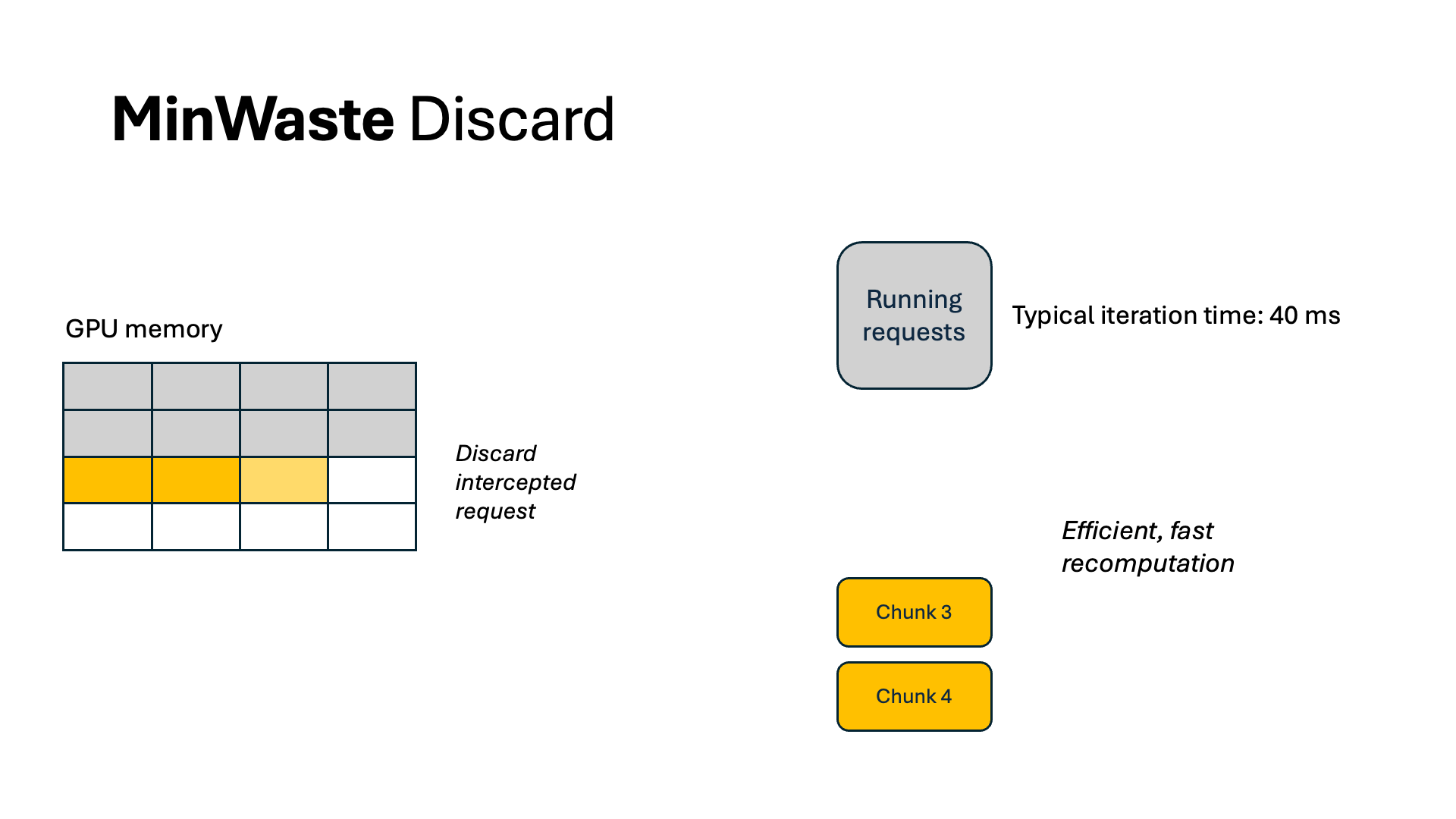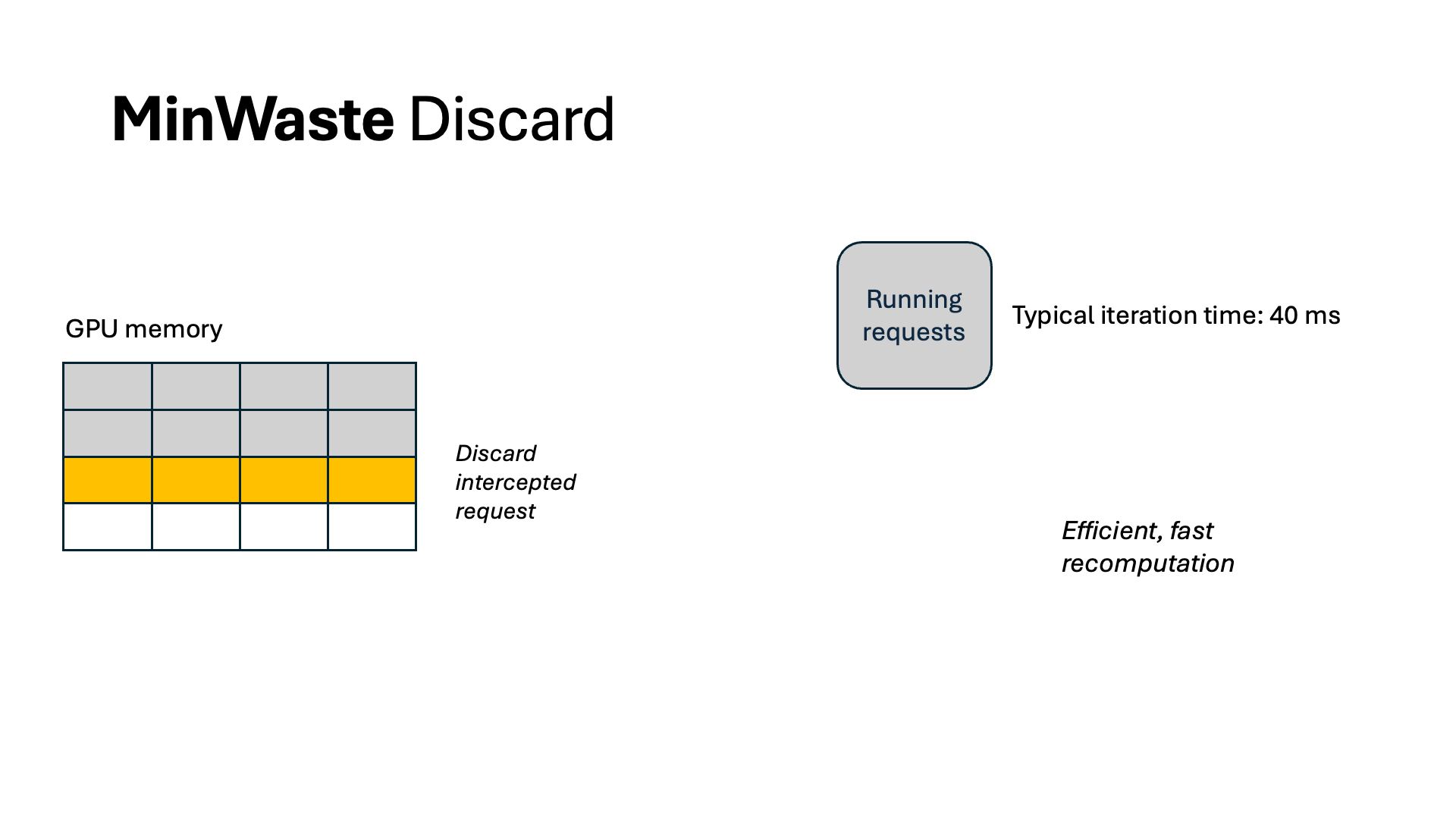
For swapping, we overlap all data communication with computation. By profiling the model and the CPU-GPU bus bandwidth, we identify a swapping budget in terms of the number of tokens allowed to swap without incurring extra latency. As long as we do not swap more than this budget, we can completely eliminate all waste from swapping. Because of offline profiling, computing WasteDiscard and WasteSwap is easy and incurs no additional overhead during scheduling.
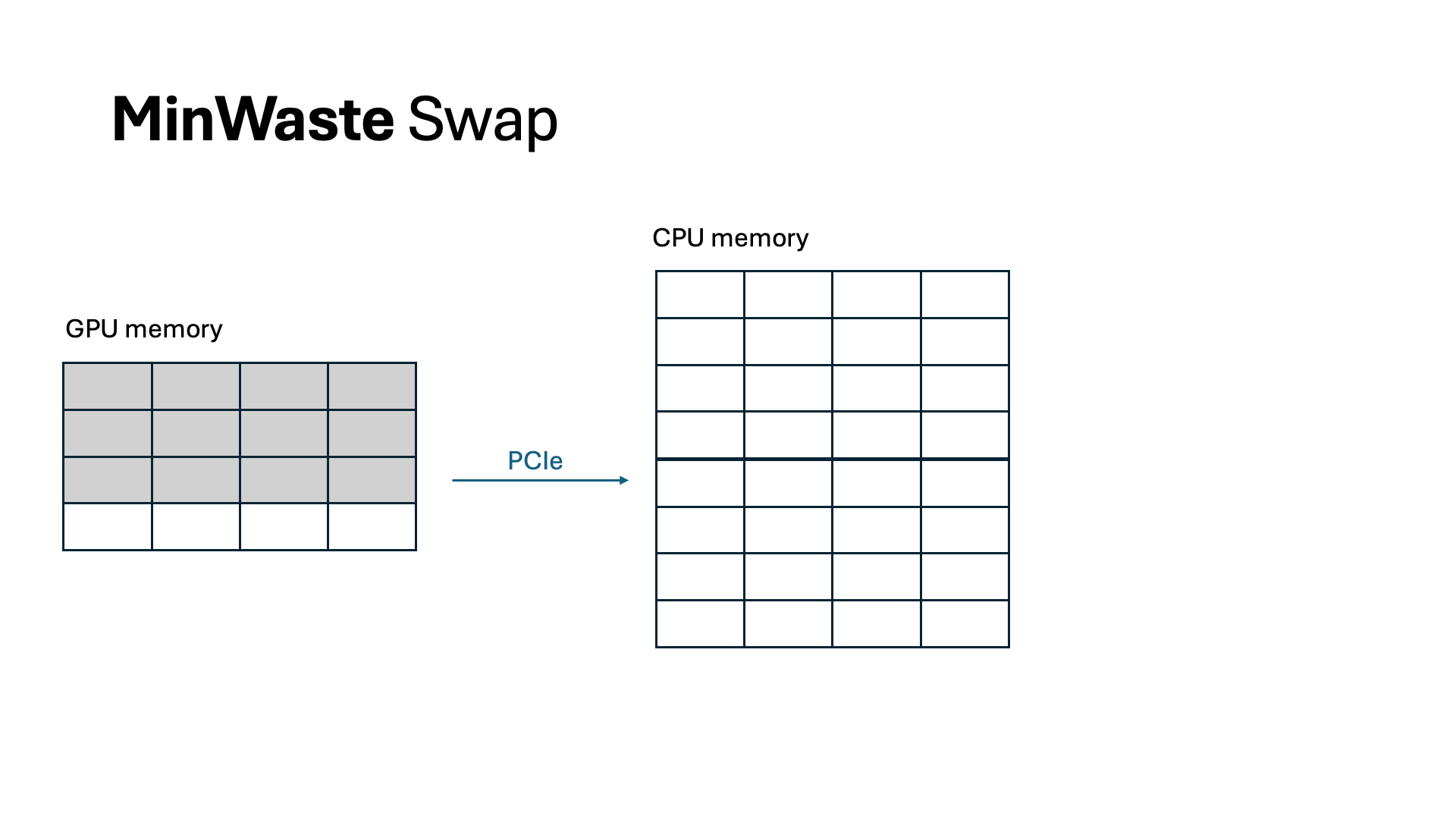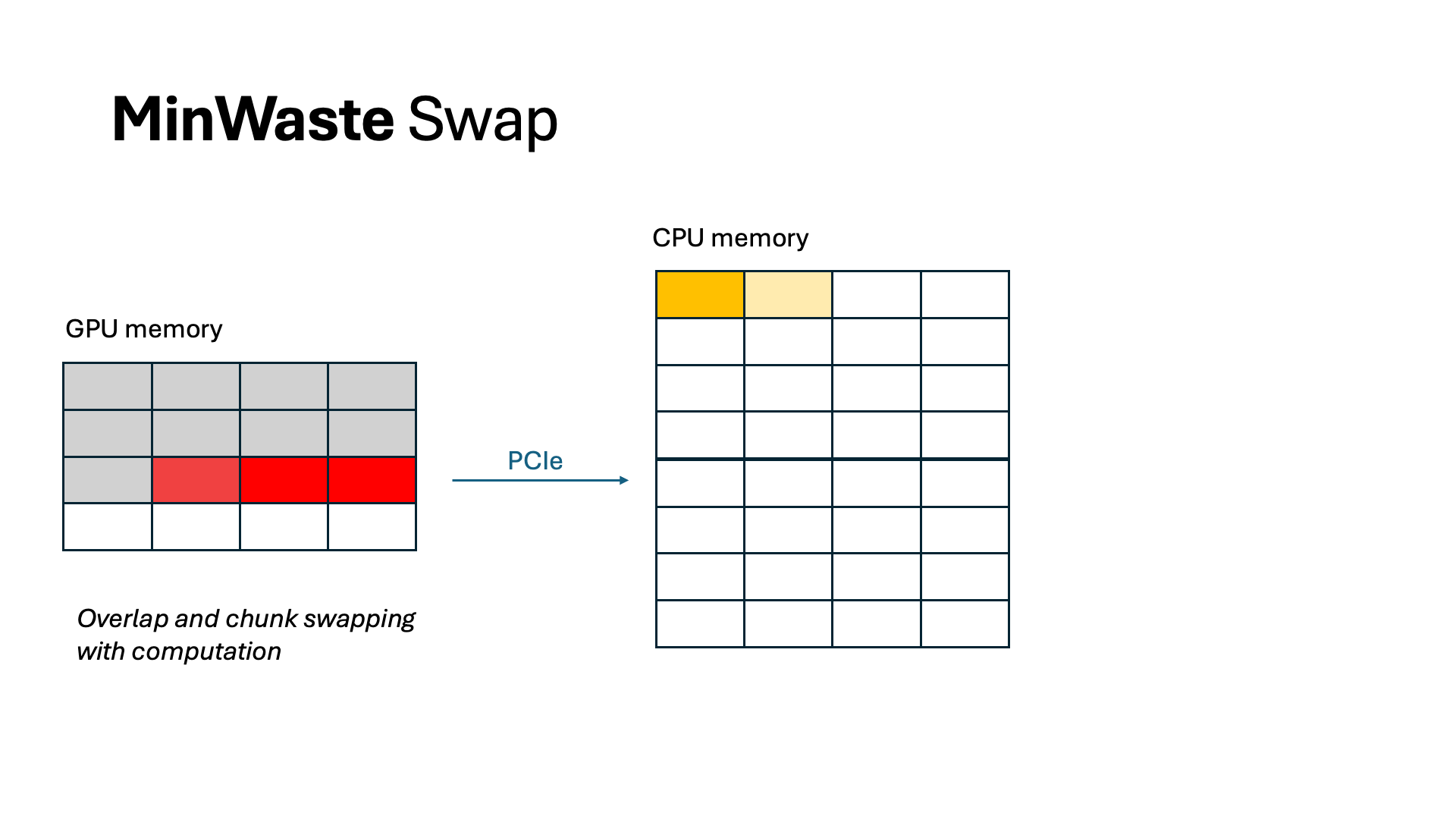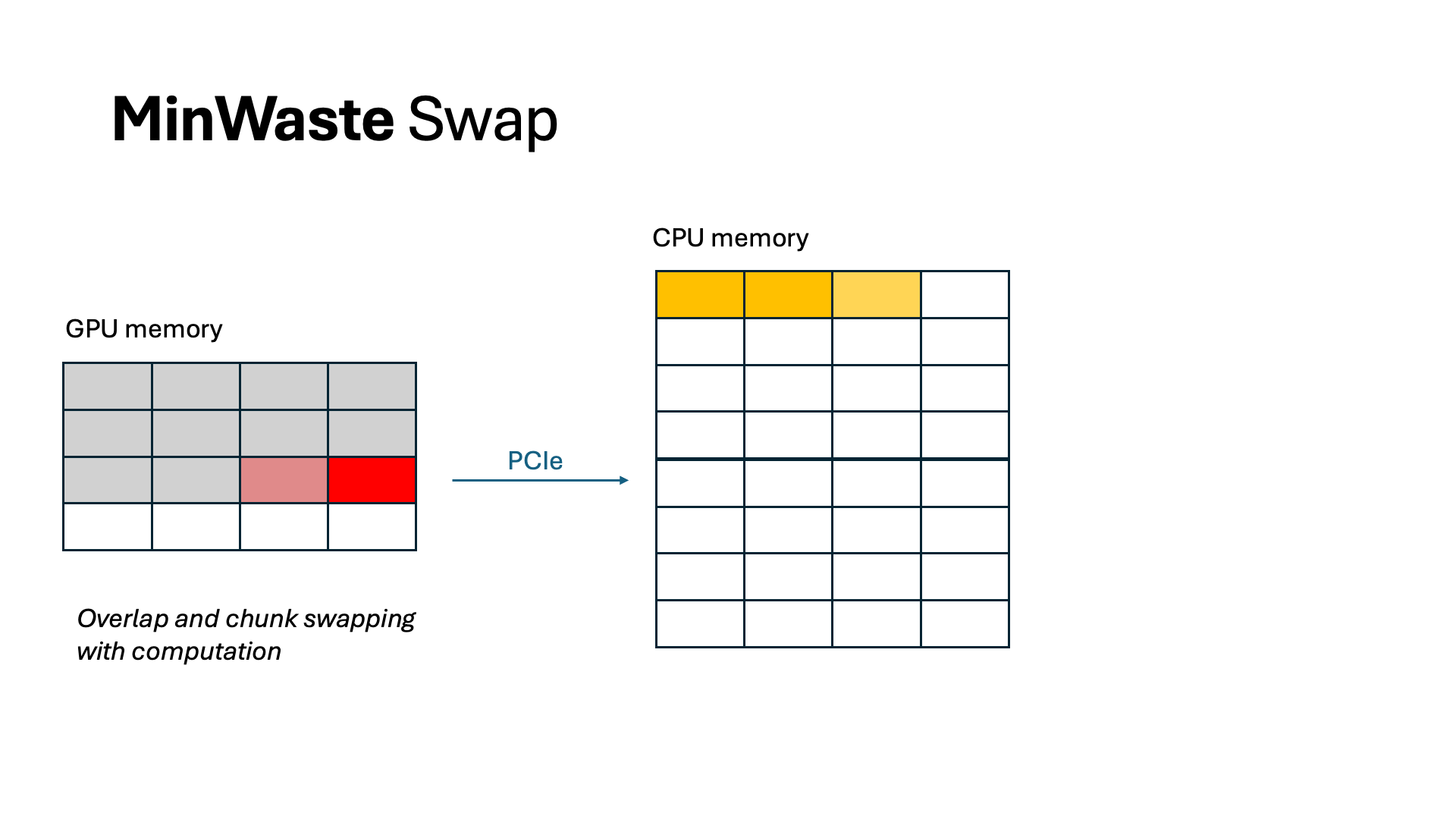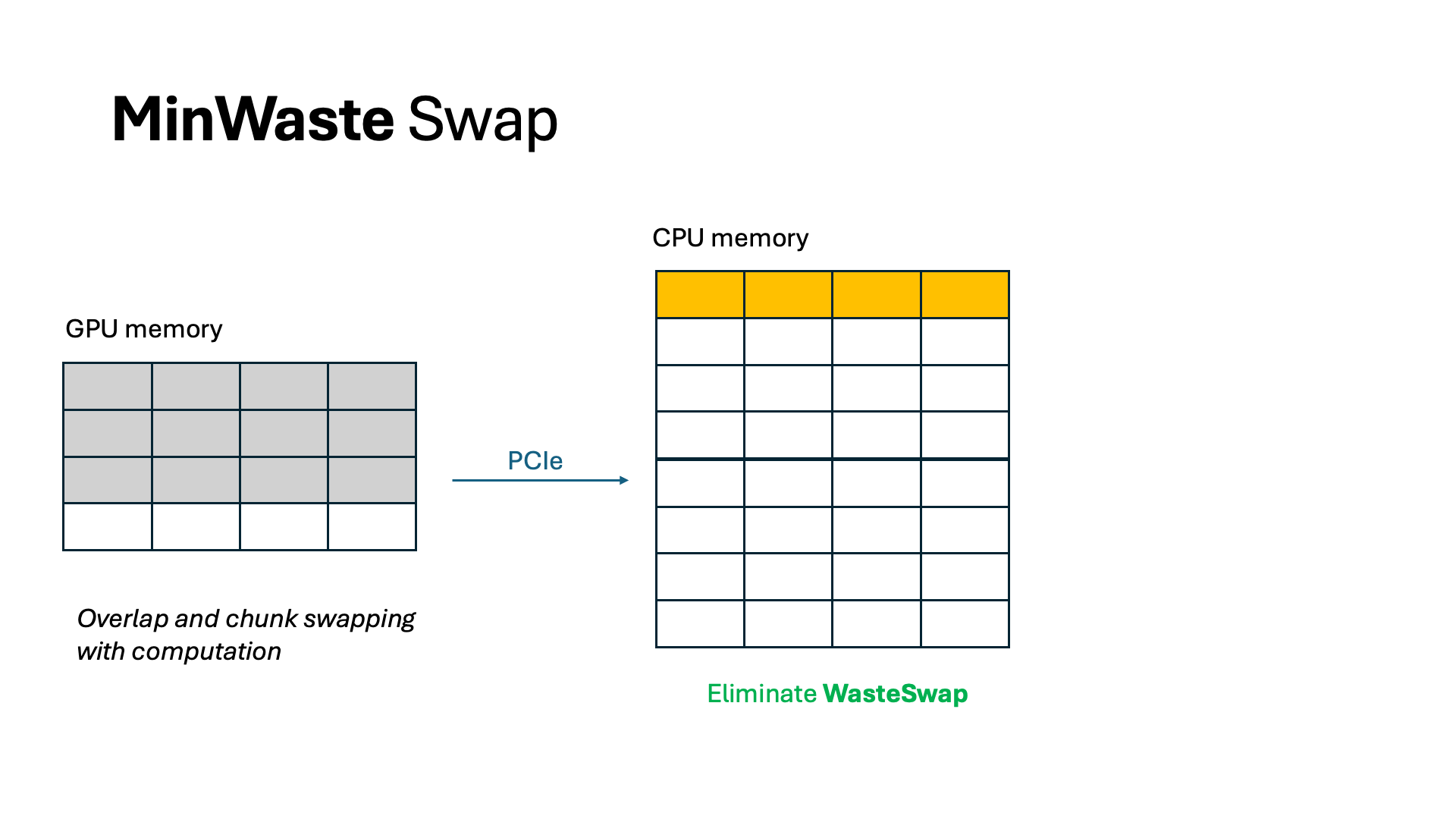
Scheduling requests to minimize GPU memory waste
In each iteration, we sort all intercepted requests in descending order based on their memory waste, which we compute as the minimum of WasteDiscard and WastePreserve. We swap out the KV context from these requests according to this order until we run out of the swap-out budget. For the remaining paused requests, we discard (preserve) their KV context if its WasteDiscard is smaller (greater) than WastePreserve.
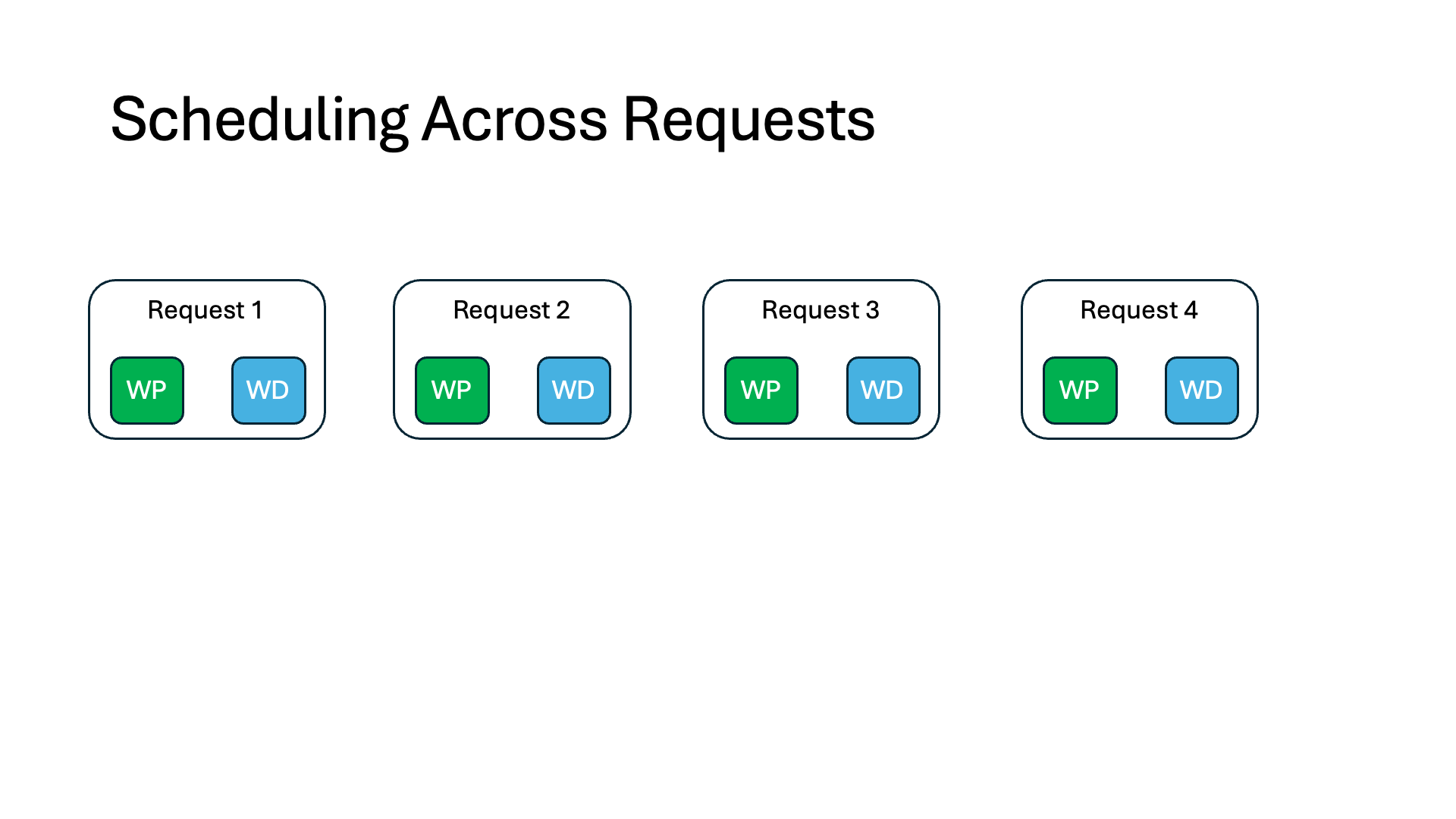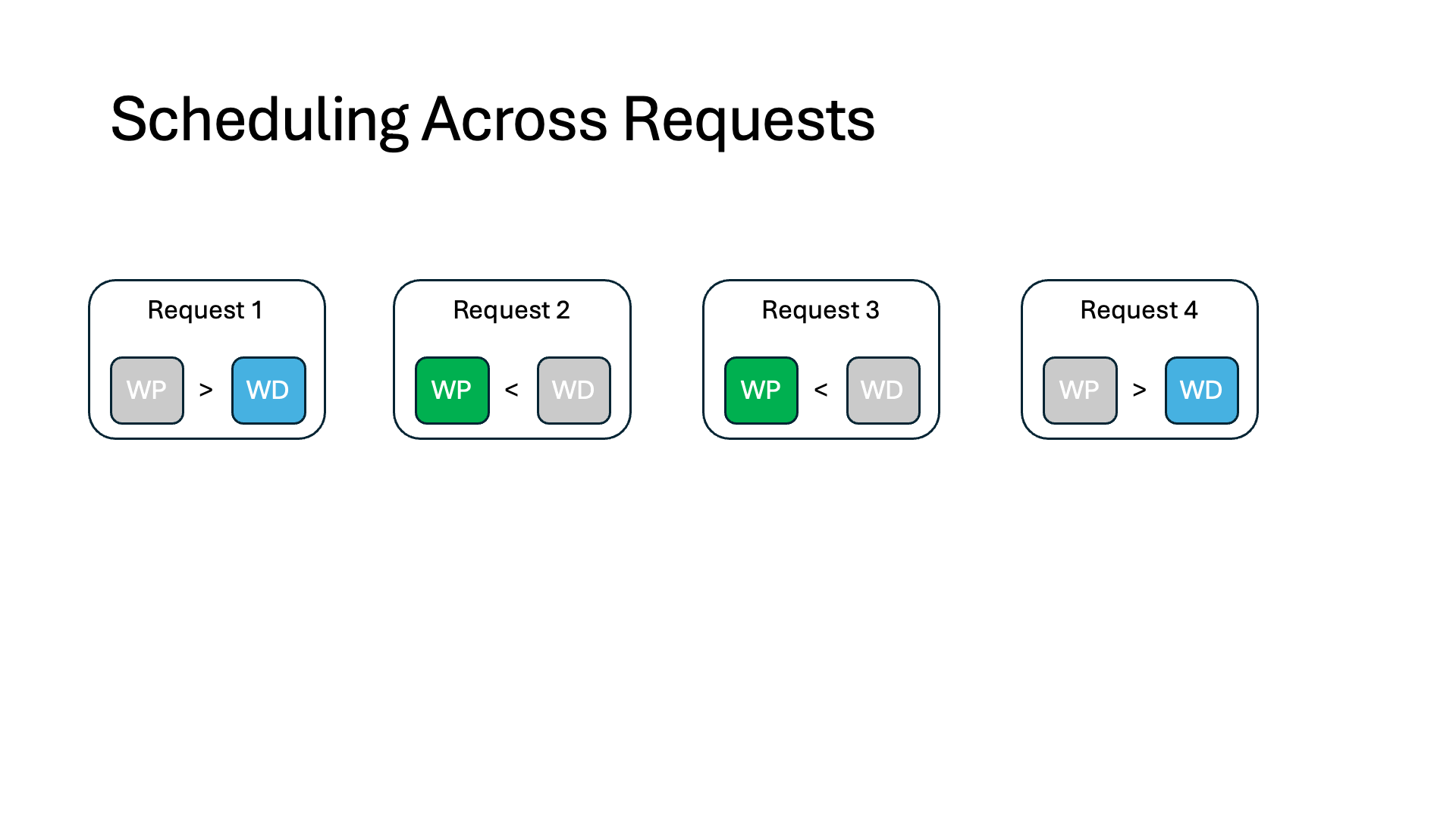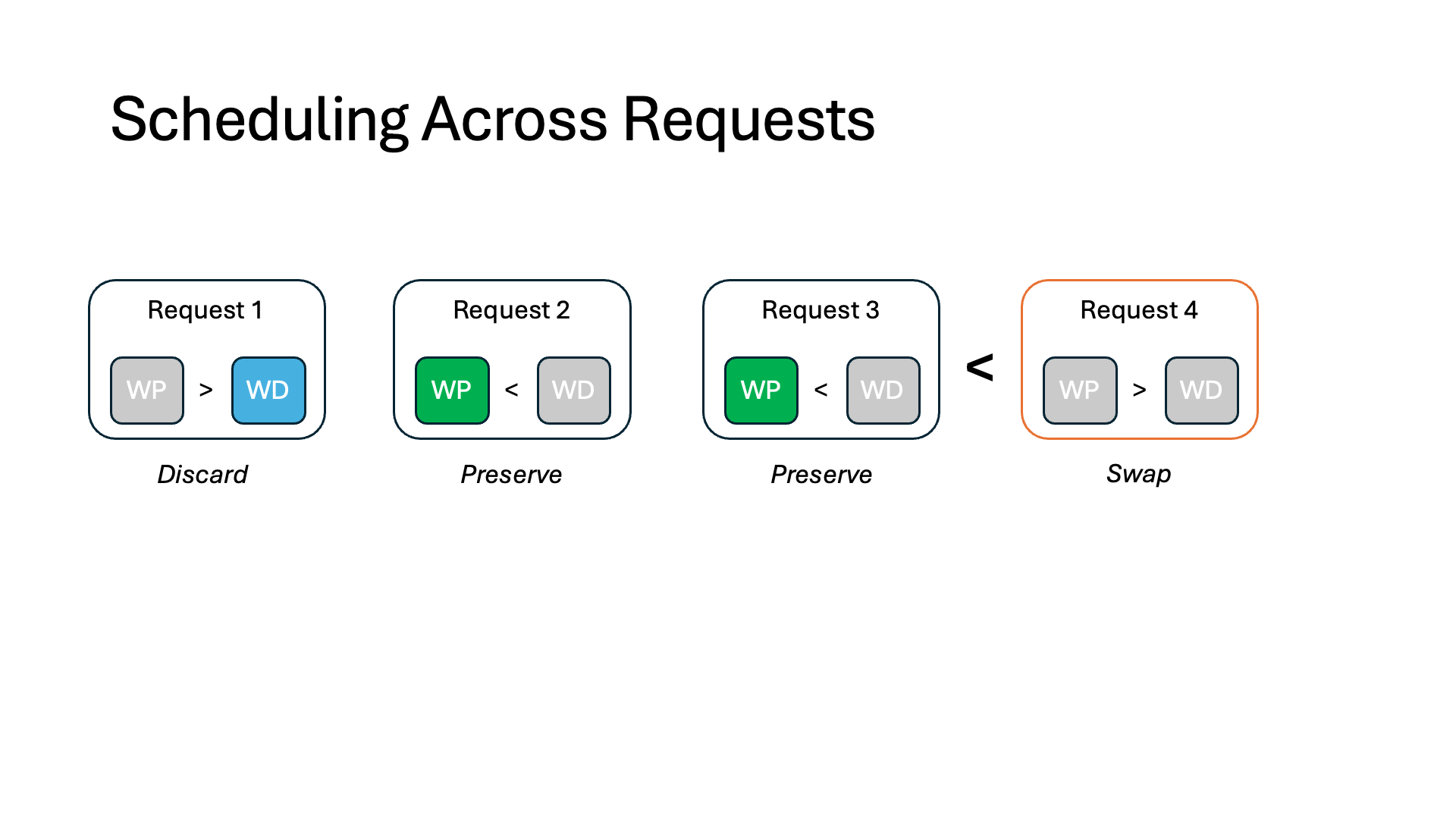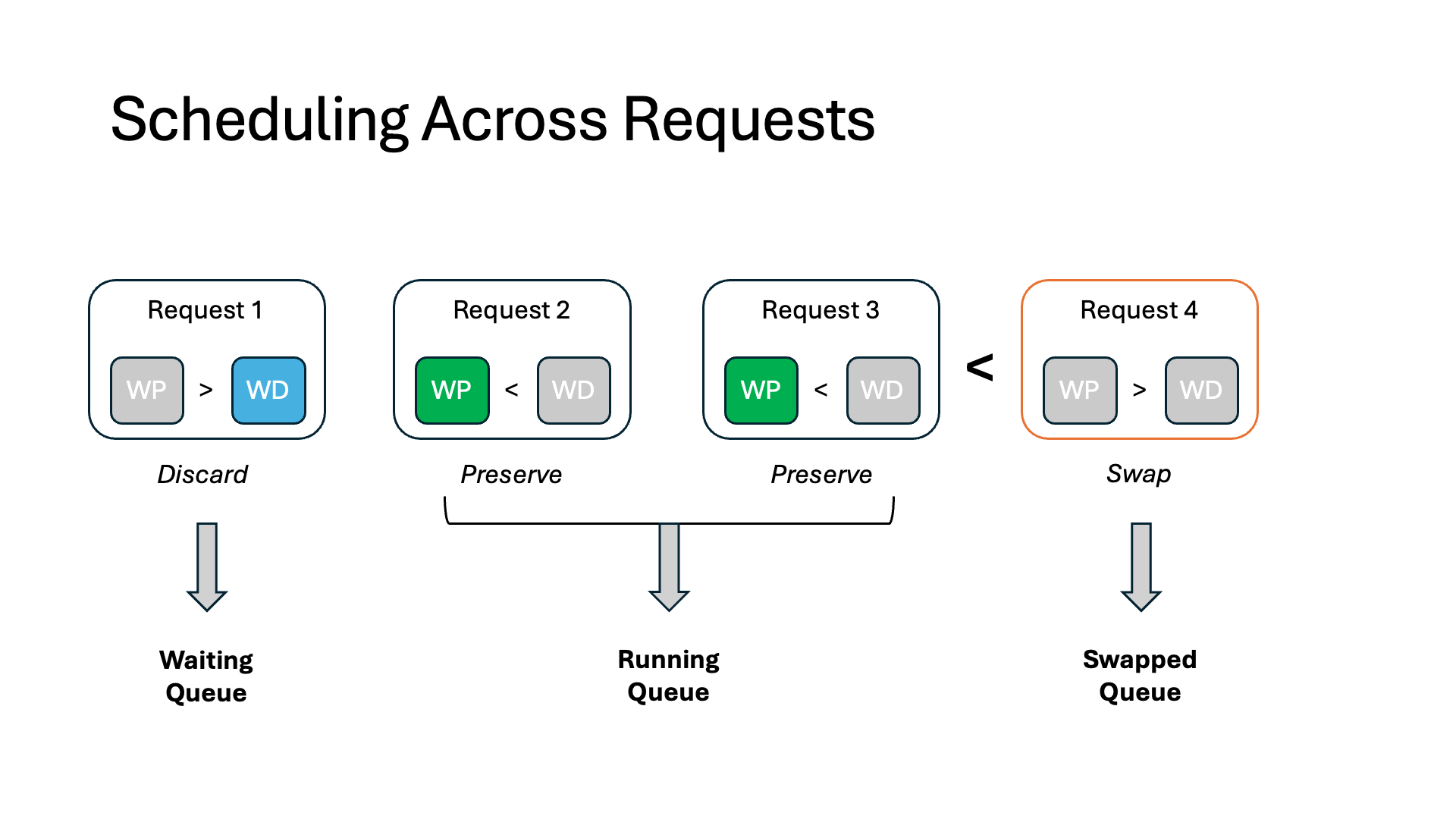
We maintain three queues: a running queue for all active requests, a waiting queue for all un-served and discarded requests, and a swapped queue for all requests in CPU memory. We follow FCFS scheduling based on the request’s original arrival time to ensure fairness.
Results
We compare against four baselines:
- vLLM (SoTA) – treating interceptions the same as completion
- ImprovedDiscard – discards token states but keeps original arrival time
- Preserve – keep all token states in memory
- Swap – offload all token states to CPU memory
For our evaluation, we compose a dataset of the six augmentations we studied.
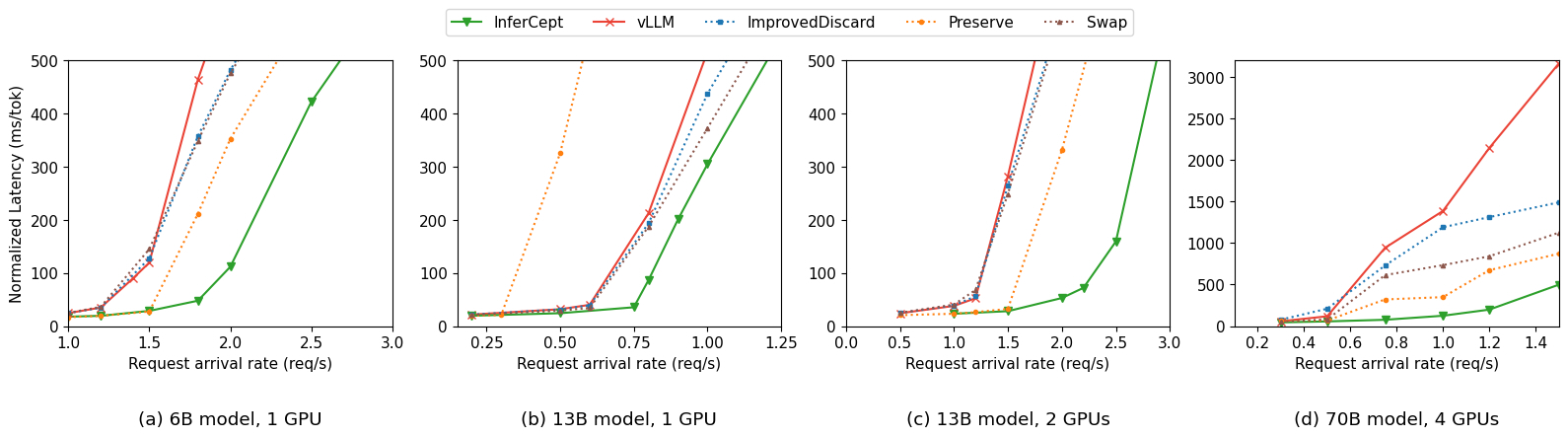
InferCept sustains 1.6x-2x higher request arrival rates at the same low latency as vLLM, while completing 2x more requests per second. It also has 1.9x-5.7x lower normalized latency per output token. These findings hold for larger models and for distributed inference, where we see up to 12x lower latency.
Our Vision
We see augmented LLM, or augmented models in general, to be the future, whether it’s with simple tools like calculators, complex multi-agent systems, non-LLM models, or physical environments. As LLMs become further embedded in our lives, they will need to interact with private data, custom applications, and physical environments. Additionally, the cost of training and serving large models keeps increasing. A promising way to make AI/ML more accessible is to use smaller and/or single-modality models that are augmented with various other models and tools as needed. For these reasons, the interactions between LLMs and the outside world must be studied and optimized to satisfy increasingly complex tasks.
If you use InferCept for your research, please cite our paper:
@inproceedings{abhyankar2024infer,
title="{INFERCEPT: Efficient Intercept Support for Augmented Large-Language Model
Inferencing}",
author={Reyna Abhyankar and Zijian He and Vikranth Srivatsa and Hao Zhang and Yiying Zhang},
booktitle={Proceedings of the Forty-First International Conference on Machine Learning (ICML'24)},
year={2024},
month=Jul,
address={Vienna, Austria},
}