Author: Vikranth Srivatsa, Yiying Zhang
This is joint work with Together AI.
Paper by Zelei Shao, Vikranth Srivatsa, Sanjana Srivastava, Qingyang Wu, Alpay Ariyak, Xiaoxia Wu, Ameen Patel, Jue Wang, Percy Liang, Tri Dao, Ce Zhang, Yiying Zhang, Ben Athiwaratkun, Chenfeng Xu, and Junxiong Wang.
TLDR: Reinforcement learning (RL) post-training spends most of its wall-clock time in the “rollout” phase generating answers, and a few very long generations dominate every training step. We designed DAS [MLSys ‘26], a distribution-aware speculative decoding framework that speeds up RL rollouts without changing what the model learns. DAS uses a training-free drafter that continually rebuilds itself from recent rollouts and spends its speculation budget on the long generations that set the pace, cutting rollout time by up to 50% while keeping the training curve identical to the baseline.
RL Post-Training Is Bottlenecked by the Rollout
Reinforcement learning has become a standard way to post-train large language models. After pretraining, the model is improved by having it generate answers, scoring those answers with a reward (a correct math solution, a program that passes its unit tests), and updating the weights so high-reward answers become more likely. Models like DeepSeek-R1 are trained this way.
This loop has a phase structure. Each iteration runs three steps: generation, where the model produces answers for a batch of prompts; preparation, where those answers are scored; and training, where the weights are updated. The generation step, called the rollout, is the expensive one. It is autoregressive, meaning the model produces one token at a time, so a long answer takes many sequential model passes. In modern RL training the rollout often accounts for more than 70% of total wall-clock time, more than backpropagation and the weight updates combined.
The rollout has a specific bad property: a long tail. Within one batch, most prompts produce short answers, but a few produce very long ones. RL training is synchronous, so the training step cannot start until every answer in the batch is finished. The few longest generations (the stragglers) therefore set the wall-clock time of the whole step. As the short answers finish, their slots go idle and the effective batch size collapses, so the GPUs spend the end of every rollout running just a handful of long sequences at very low utilization.
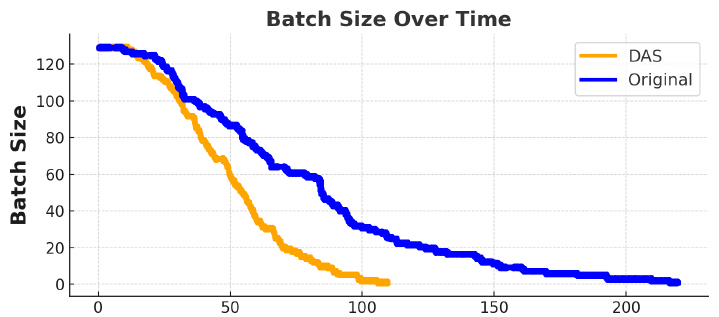
Figure 1: Effective batch size during a rollout. Short sequences finish first, so the batch shrinks and a few long stragglers determine how long the step takes. DAS (orange) clears the batch substantially faster than the baseline (blue).
A natural way to make autoregressive generation faster is speculative decoding, which we describe below. The question this work asks is how to make speculative decoding actually work for the RL rollout, which behaves very differently from the online serving setting it was designed for.
Three Things That Make RL Rollouts Different
Borrowing serving techniques directly does not work, for three reasons.
The metric is makespan, not per-request latency. Online serving optimizes the latency of each individual request. RL training waits for the slowest member of a fixed batch, so what matters is finishing the long generations, not shaving milliseconds off the short ones. Speedups should be aimed at the tail.
The same prompts come back every epoch. Unlike serving, where each user request is different, RL revisits the same dataset across training epochs. Generations for the same prompt are highly similar from one epoch to the next, so recent history is a strong predictor of what the model is about to generate. This is an opportunity that serving systems have no reason to exploit.
The model keeps changing. In serving the model is fixed. In RL the weights are updated every step, so the policy drifts. Generations from many steps ago stop resembling current ones, which means anything learned or tuned on old rollouts goes stale.
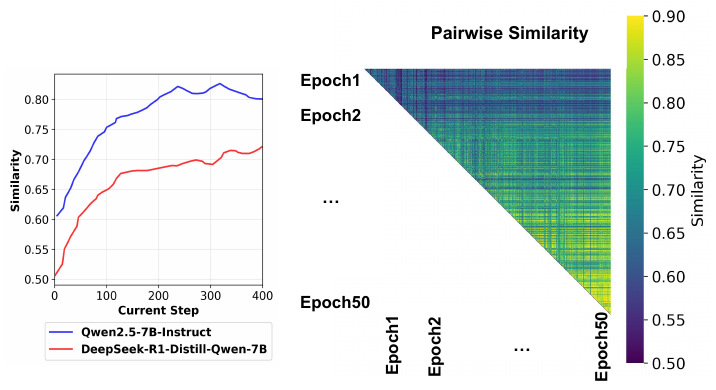
Figure 2: Left: content similarity between a generation and recent history rises and stays high as training proceeds. Right: pairwise similarity across 50 epochs. The bright band near the diagonal shows generations are most similar to recent epochs, and similarity fades with distance. Recent history predicts the next generation well, but only recent history.
Together these say: speculation should be driven by recent rollout history, refreshed continuously as the policy moves, and concentrated on the long generations.
Background: Speculative Decoding and Suffix Decoding
Speculative decoding speeds up autoregressive generation by adding a small fast drafter that proposes several next tokens at once. The large target model then verifies all of them in a single parallel pass, keeping the longest prefix that matches what it would have generated and discarding the rest. Each accepted token replaces a sequential target-model step with a piece of a single parallel one, so the wall-clock cost of generating a sequence drops whenever the drafter guesses well. The verified output has exactly the same distribution as standard decoding, so speculative decoding is lossless: it never changes what the model produces or learns. The classic drafter is a small neural network (e.g., a distilled model or EAGLE) trained to mimic the target.
Suffix decoding replaces the neural drafter with a non-parametric one: an index over text the system has already seen. Given the last few generated tokens (the current suffix), the index looks up the most frequent continuation observed in the corpus and proposes it as the draft. The corpus can be prior outputs of the same model, the prompt itself, or a cache of past requests. Because the drafter is just a lookup, there is no drafter model to train, no extra GPU pass to run the drafter, and the index can be updated incrementally as new text arrives. Suffix decoding is especially effective when generations are repetitive or recur across requests, which is exactly the regime an RL rollout sits in: the same prompts come back every epoch, and the model’s outputs for a given prompt are highly similar across nearby steps. DAS builds on this idea, using a per-problem suffix tree over recent rollouts as its drafter.
Introducing DAS
DAS (Distribution-Aware Speculative decoding) is a speculative decoding framework built for the RL rollout. It has two parts: a training-free drafter that rebuilds itself from recent rollouts, and a length-aware policy that decides how much speculation each prompt gets.
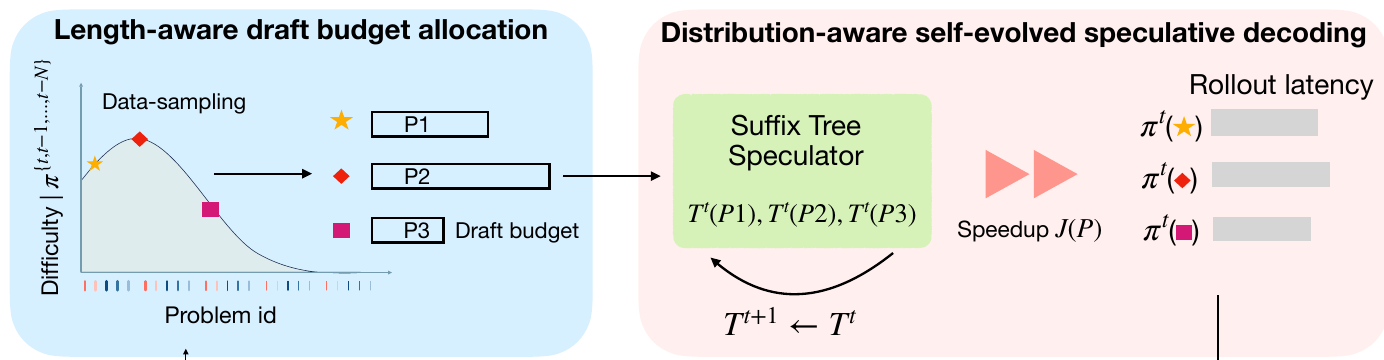
Figure 3: DAS overview. Left: a length-aware policy estimates each problem's length from recent rollouts and gives long or hard problems a larger speculation budget. Right: a suffix-tree speculator, rebuilt incrementally from the most recent rollouts, proposes multi-token drafts that the target model verifies in parallel.
A Training-Free, Self-Evolving Drafter
The usual drafter is a small neural network, such as EAGLE, trained to imitate the target model. In RL that is a poor fit. Because the policy drifts, a drafter trained on earlier checkpoints accepts fewer and fewer of its guesses over time, so it must either be retrained repeatedly during training or tolerate falling speedups. Either way it adds compute and engineering to a phase that is already the bottleneck.
DAS uses no neural drafter at all. Instead it keeps a suffix tree built from a sliding window of recent rollouts. A suffix tree is an index over recently generated text that, given the last few tokens, instantly returns the most frequent continuation. It is cheap to update one token at a time, so DAS refreshes it every iteration from the newest rollouts. The drafter is therefore always aligned with the current policy without any training. Because the same prompts recur across epochs (the second observation above), these recent-history continuations are accurate guesses even as the model evolves.
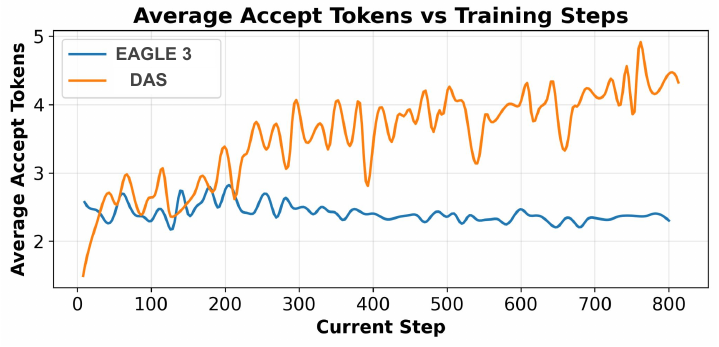
Figure 4: Average accepted tokens per verification round during RL training. A static trained drafter (EAGLE) stays flat, while the DAS drafter improves as it keeps absorbing recent rollouts. More accepted tokens means fewer target-model passes and lower rollout latency.
A natural alternative index is a suffix array, which is more space-efficient. The problem is that suffix arrays are static: absorbing fresh rollouts every iteration requires partially rebuilding them, which is exactly the operation RL needs to be cheap. The suffix tree updates incrementally instead, so it stays fast on exactly the workload RL produces.
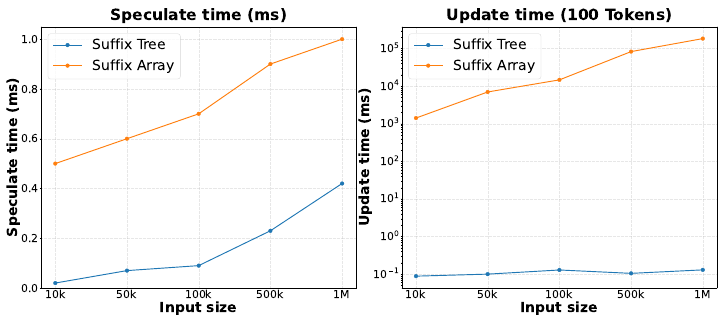
Figure 5: Suffix tree vs. suffix array. The tree is 2–20x faster at proposing drafts and, crucially, keeps sub-millisecond update cost while the array's rebuild cost grows by orders of magnitude with corpus size.
DAS also scopes the index per problem rather than keeping one global index over all rollouts. A global index mixes in continuations from unrelated problems and from stale policies, both of which lower the acceptance rate. A per-problem index stays small, current, and on-topic.
Spending the Draft Budget on the Long Tail
Speculating uniformly on every prompt wastes effort. Short generations finish quickly no matter what and barely contribute to the step time, so speculation on them buys almost nothing. The long stragglers are what the training step waits for, so every token saved there shortens the whole step.
DAS allocates a larger, more aggressive speculation budget to prompts predicted to be long or hard, and little or none to short ones. The difficulty is that generation length is highly variable, so the budget cannot be set once and left alone.
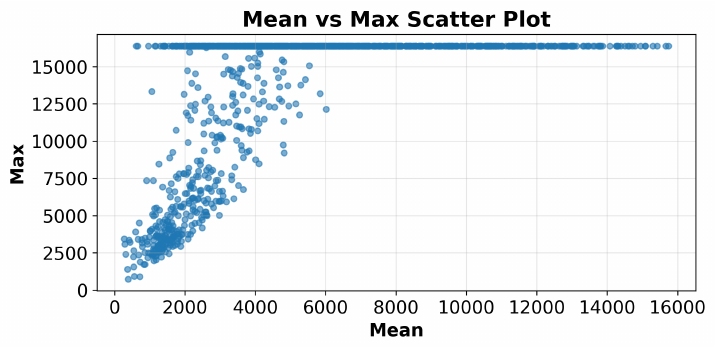
Figure 9: Each point is one problem; the axes are its mean and maximum generation length across epochs. The wide spread and high maximums show that generation length is dynamic and cannot be predicted from a single fixed estimate.
DAS handles this with a runtime length predictor. It sorts prompts into Long, Medium, and Short classes, each mapped to a speculation budget, initializes the class from the prompt’s history, and adjusts the class on the fly as the actual generation length reveals itself. A short formula derived from a simple linear model of decode latency sets how aggressive the budget should be for each class, so the extra verification cost stays worth it.
Results
DAS is built on the VeRL RL training framework and the vLLM inference engine. It is evaluated on two representative RL workloads, mathematical reasoning (One-Shot-RLVR on DeepScaleR-style problems) and code generation (DeepCoder), with models from 1.5B to 14B parameters, on clusters of up to six 8×H100 nodes. Every reported time is actual wall-clock rollout time, including batching, scheduling, and verification.
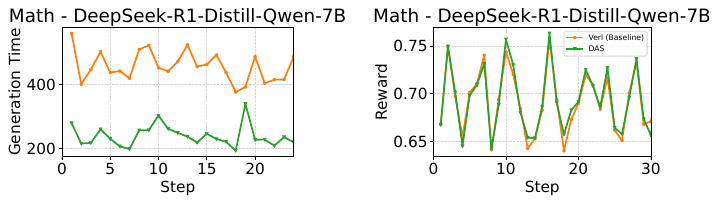
Figure 10: Math RL with DeepSeek-R1-Distill-Qwen-7B. Left: generation time per training step, baseline vs. DAS. Right: reward per step. DAS cuts generation time by more than 50% while its reward curve lands exactly on the baseline's.
The headline result is that DAS reduces rollout generation time by more than 50% on math RL, and by about 25% on code RL, while the reward curve is indistinguishable from the no-speculation baseline. This is the point of using speculative decoding: it is lossless, so training quality is preserved exactly while the wall clock shrinks.
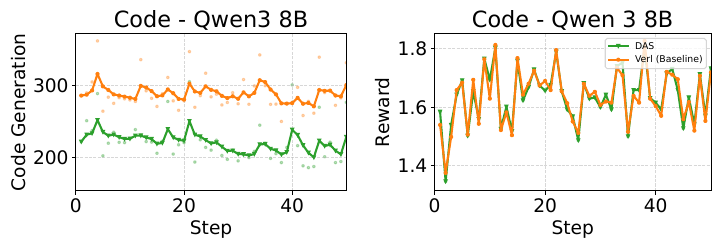
Figure 11: Code RL with Qwen3-8B. DAS lowers generation time substantially while matching the baseline reward, showing the speedup carries over to a different task and reward signal.
An ablation shows why being distribution-aware matters. A version of DAS with an unbounded speculation budget lets the suffix tree propose as many tokens as it can. Proposing too many tokens makes verification expensive and eats into the gain. The length-aware budget, which spends aggressively only where it pays off, is up to 15% better than the budget-agnostic version.
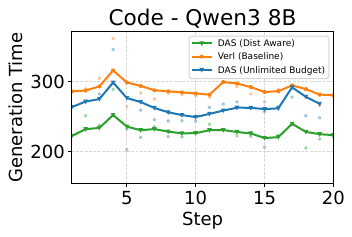
Figure 12: Ablation on Qwen3-8B code RL. The length-aware budget (green) beats both the baseline (orange) and an unbounded speculation budget (blue), which over-proposes and pays too much verification cost.
The speedup also holds as the maximum generation length grows from 8k to 16k tokens, and as the effective batch size shrinks from 32 to 16, because the gain comes from cutting sequential target-model passes on the long tail rather than from any particular batching regime.
Our Vision
RL post-training is becoming a primary cost of building capable language models, and the rollout is most of that cost. The useful idea here is that the RL rollout is not just a serving workload run in a loop. It has structure that serving does not: a fixed makespan to beat, the same prompts returning every epoch, and a model that changes underneath you. DAS turns each of those properties into leverage, using recent history as a free, self-updating drafter and aiming the speculation budget at the generations that actually set the pace. As RL training scales, we think co-designing the rollout with the training loop, rather than reusing serving systems unchanged, is where much of the remaining speedup will come from.
If you use DAS for your research, please cite our paper:
@inproceedings{shao2026beat,
author = "Shao, Zelei and Srivatsa, Vikranth and Srivastava, Sanjana and Wu, Qingyang and Ariyak, Alpay and Wu, Xiaoxia and Patel, Ameen and Wang, Jue and Liang, Percy and Dao, Tri and Zhang, Ce and Zhang, Yiying and Athiwaratkun, Ben and Xu, Chenfeng and Wang, Junxiong",
title = "Beat the long tail: Distribution-Aware Speculative Decoding for RL Training",
booktitle = "Proceedings of the 9th Annual Conference on Machine Learning and Systems (MLSys)",
year = "2026"
}