Author: Qi Qi, Reyna Abhyankar, Yiying Zhang
Ever ask an AI to tackle a tough research question and find yourself waiting… and waiting? You expect a smart, quick response, especially when the answer is needed for urgent tasks like debugging a production issue or analyzing a sudden market shift. When an AI takes too long, it breaks your workflow. In our new pilot study, “Demystifying Delays in Reasoning”, we dug into why these slowdowns happen and found the bottleneck isn’t where you might think.
We analyzed three powerful reasoning systems: OpenAI’s o3-Deep-Research, GPT-5, and the open-source LangChain Deep Research Agent (LangChain-DR), using requests from the DeepResearch Bench. We broke down the total run time into individual thinking and actioning steps in three categories: reasoning (“thinking”), web searching (tool use), and final answer generation. Our results suggest a different perspective from a common assumption.
Key finding: The process of searching the web and retrieving information can be a more significant time sink than the model’s internal “thinking”.
Pilot Study Methodology
DeepResearch Bench consists of 100 PhD-level research tasks crafted by domain experts. We randomly sampled 10 tasks and grouped them into ’long’ and ‘short’ categories based on their typical completion times. For OpenAI’s o3-DR and GPT-5, we used the official response API to capture the timing and token count of each internal event. For the open-source LangChain-DR, we instrumented its source code to get the same level of detail. This allowed us to precisely attribute latency and cost to the distinct phases of the reasoning process, giving us the data behind the visualizations you see here.
Where Does the Time Go?
As the chart above illustrates, web search can consume up to 73% of the total time for a model like GPT-5. The model spends the vast majority of its time waiting for external tools, not on its own internal reasoning. This suggests that some of the biggest performance gains may come from smarter and more efficient tool use.
A Close Look into Task Timelines
To understand how events unfold over time for each system, we performed a detailed timeline analysis with one randomly selected task. Note the frequent, small web searches for o3-DR, the long, sequential searches for GPT-5, and the parallel searches for LangChain-DR.
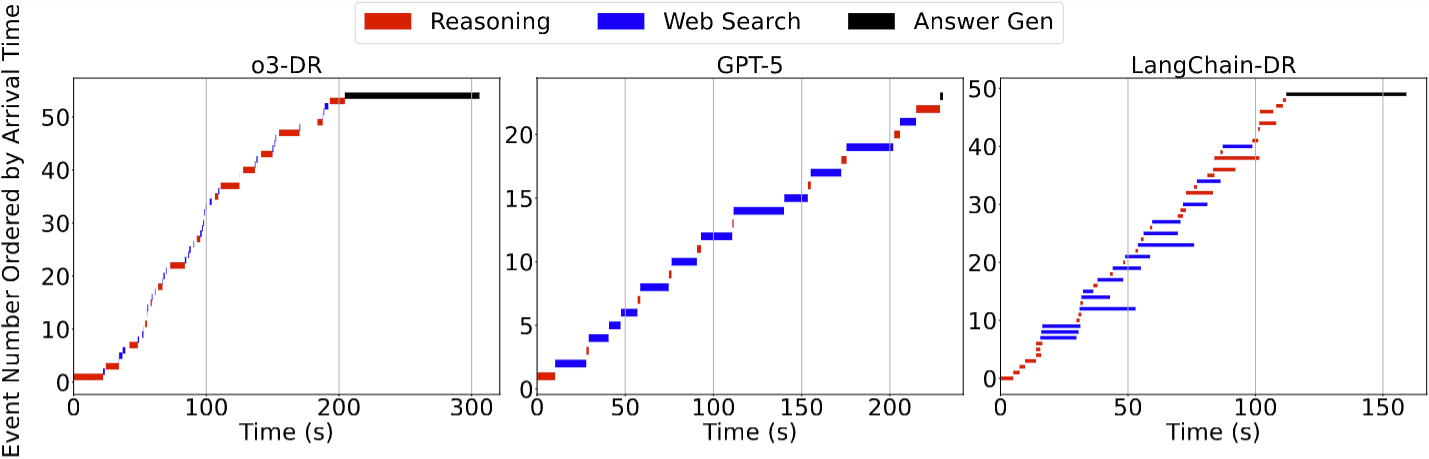
The timeline view makes the difference clear. o3-DR spends more time in the reasoning phase, interspersed with quick web searches. In contrast, GPT-5 and LangChain-DR are characterized by long, sequential web search calls. LangChain-DR shows some asynchronicity with parallel searches, but the tool-use latency is still a major factor.
The Token Tax: How Retrieval Inflates Cost
Our other major finding is that final answer generation uses the most tokens. This is because all the content gathered from web searches is fed back to the model as context. Use the slider below to see how the amount of retrieved webpage content can dramatically increase the token count and cost of the final answer.
Estimated Answer Gen Tokens
~13,300
Estimated Cost
~$0.78
What This Means for the Future of GenAI
Our research shifts the conversation around GenAI performance. While we chase after more powerful and efficient models, we may be overlooking other important factors like how these models access external information. The key takeaway is that optimizing tool use—making web searches faster and more efficient—could be one of the most impactful ways to speed up AI reasoning systems. Here’s a breakdown of what that means for developers, users, and researchers:
- For Developers: The focus could shift towards intelligent tool orchestration. Can we parallelize searches more effectively? Can we pre-fetch information? Can we design more concise retrieval prompts to reduce the “token tax”?
- For Users: This helps explain why some AI queries feel instant while others drag on. It’s not just the complexity of your question, but the complexity of the information retrieval required to answer it.
- For Researchers: This opens a new frontier for optimization. Improving how agents interact with their tools could lead to more significant real-world latency improvements than marginal gains in model speed.
Ultimately, for AI to become seamlessly integrated into time-sensitive workflows like customer support, incident response, or interactive coding, speed is paramount. Our study reminds us that in the race for faster AI, we need to look beyond the model itself and consider the entire system.